-
去年在研读营的发言摘录
(就,觉得自己还挺有洞察力的……)
熊节:我在看《赛博无产阶级》这本书的时候有一个观察,就是它用马克思的理论在呼吁赛博空间的无产阶级联合起来,但关于“如何联合起来”这个问题是缺乏回答的。可能跟我来自产业界的背景有关,我看到这本书的时候就会想,我们认识到问题的存在了,那么接下来应该怎么办呢?这个“怎么办”的问题,我觉得仍然缺乏一个令人满意的答案。
无产阶级应该如何联合起来,这个问题一直找不到好的答案,这让我们隐约看到,背后有一种力量的存在。昨天我跟吴老师讨论传播学的时候,我们就谈到一个现象:偏右翼的、偏自由主义的、偏市场的这些传播学学者,他们可以很自然地去做跟市场有关的研究,很自然地得到市场的资助,形成一个生态,不断去强化他的影响力。而左翼的学者,当他们要谈论社会问题的时候,就会遇到更多的阻力,需要更努力地去克服困难才能做这件事。在赛博空间的无产阶级联合这个问题上,我们也看到一种类似的现象:资本的联合、资本和权力的联合、资本和市场的联合,好像不需要特别的努力,很自然地就联合起来了;而弱势群体则有着各种各样的隔阂,很难形成一个联合的、共同的网络空间,很难形成合力。我觉得,这种现象不应该解释为赛博无产阶级是一盘散沙,这不是一个合理的解释。我认为这种现象的背后,是有一种力量在促成资本那一方的联合,并且打压无产阶级这一方的联合。这种力量是什么?我认为这是一个值得探索的问题。
现在中国的互联网已经形成了一种中心化的结构。这方面可能邱老师的研究会给我们一些线索:中国的互联网在很早的早期(2000年代初期),是有着草根的、自发的联合的形式的。但很快我们就发现,网络在逐渐中心化,并且每一个中心、每一个热点都是资本在推动。在今天这样一个已经中心化的网络生态下,用什么方式去创造一个无产者的联合,这是一个难题。因为这种无产者的联合,是现在的网络中心所不乐见的。那么我们用什么方式去联合?是创造一个新的中心?还是用一种去中心化的方式来形成分享和共识?这可能也是一个需要讨论的问题。
当我们想去探讨赛博空间的无产阶级如何联合的时候,我们首先要意识到,这种联合并不是所有人都喜闻乐见的,它可能是资本所不愿意看到的。在这种情况下,我们用什么去驱动这种联合的形成,使之不会轻易被破坏,这既是一个学术理论问题,同时也是一个技术问题。这里面需要一个有效的组织方式。因为我们现在看到资本的力量,资本和权力的结合,这个力量是非常庞大的。并且我们谈论的现在也不是工厂里面成千上万的工人每天在同一个地方工作这样的形态,我们谈论的是赛博空间的无产阶级,这种新的无产阶级形态一定需要新的组织方式。我不知道答案是什么,我觉得它可能需要不同的思考。
-
2018年读过的好书
去年发生了很多事。在忙碌奔波之中,好歹算是保住了底线,读了57本书。和工作相关的书,读得越来越少了……
历史故事
- 安禄山叛乱的背景 - 写得真好啊,史实详尽,技术严密,故事讲得又精彩。想到自己一辈子也写不出这么好的历史书,就觉得好伤心💔
- 国盗物语 : 织田信长 - 好喜欢光秀啊…像信长和秀吉那样的人才能成为霸主吧?但是光秀那样的生活方式才值得羡慕不是吗?
- 洪业 : 清朝开国史 - “更替”不是一个瞬时的事情,而是一个长达数十年的过程,从这个角度来看,愈发感叹历史的丰富
半真半假的历史故事
关于敌人和斗争
- 共享经济没有告诉你的事 - 由资本和欺骗包裹的伪共享经济已经四面楚歌了,现在谁找到靠谱的替代方案,谁就能占据下一个风口
- 休克主义 : 灾难资本主义的兴起 - 这本书最大的意义在于用无可辩驳的证据证明,新自由主义的兴起与繁荣不是偶然,不是看不见的手,恰恰相反,这是一场精心为之的阴谋。对于敌人千万不要抱任何幻想。
- Weapons of Math Destruction - 中国急需这样的左翼知识分子:对技术有深刻理解,并且能看到技术对社会造成的影响。
- 青年斯大林 - 出人意料的精彩。不过嘛,越是还原真实的革命家,就越是觉得,这帮人真的是超人啊…
纯属休闲的故事
- 坏小孩 : 推理之王2 - 哎呀哎呀好久都没有看一本推理小说看得心子把把都揪紧了
还是做了工作的唷~
- Managing the Professional Service Firm - 本主题最佳没有之一,老板必读必会
-
每个人无条件拿两千美元月薪,能拯救美国吗?
(本文首发于公众号“一颗土逗”)
几年前我第一次去美国,给我留下的第一个深刻印象就是每份菜的分量都超级大,以至于我一个人吃饭根本不敢点主菜,一份前菜加上餐厅免费的面包就能把我撑个够呛。然而刚从餐厅出来,在寒风中我就看见几个流浪汉缩在角落瑟瑟发抖,瞬间让我想起一个数据:波士顿的传教山社区(有麻省综合和布莱根这样全球顶尖大医院的社区),结核病患者比例和婴幼儿死亡率都高于古巴。我跟一个美国的同事说,你们国家只要把每盘菜的分量减掉1/3,把省下来的成本捐给穷人,就能同时解决肥胖和贫穷两大社会问题。正饱受肥胖之苦的同事无奈地耸耸肩。
不是没钱,只是有钱不给穷人花,这就是资本主义社会的现实。诚如杜工部云,“朱门酒肉臭,路有冻死骨”。技术的飞速发展,把社会整体生产率提得再高,也无非是再多生产一些注定要臭掉的酒肉,该冻死的照样冻死。在世界最富有的国家仍然随处可见的贫穷,显然不是一个生产问题,而是一个分配问题。

在他的新书《The War On Normal People》中,Andrew Yang首先用大量数据,向读者揭示了美国普通人的真实生活状态。仅举一个数据:59%的美国人没有超过500美元的存款。也就是说,日常收入的一次重大变动,就可以让超过一半的美国人陷入朝不保夕的贫穷状态。这时,科技、尤其是自动化技术的高速发展,带来了完美的“重大变动”。制造业的工人和卡车司机首当其冲地成了“被下岗”的对象,自动化的机器已经取代了超过500万产业工人的工作,近在眼前的自动驾驶技术预期还将取代350万卡车司机的工作。这些人中的很大部分无法实现再就业,只能靠失业救济和残疾补助为生。
Yang提出了一个非常现实的问题:350万人,其中94%是男性,平均年龄49岁,绝大部分只有高中学历,这样一批人如果失业在家,从前中产的生活突然变成赤贫,对于社会的和谐稳定将是巨大的威胁。他从这个出发点向富人们喊话:分配问题需要解决了,不然你们的好日子怕也过不长。
对这个分配问题,Yang提出了一个简单粗暴的解决办法:所有美国公民,不管性别、肤色、年龄、收入水平,由政府出钱,每人每月发2千美金。随后他详细解释了这个办法背后的逻辑。从经济的角度,这个办法的逻辑出人意料地巧妙:它避免了失业救济的负向激励,因为无论如何都能拿到这2千美金,所以穷人不会因此失去就业的动力;它能帮助穷人度过短期现金流的难关,从而使他们更可能选择有长期可持续性的职业,或是接受再教育;它的金额不够大,中产阶级的工作热情不会因此受到损害;最重要的是,它实施起来很容易,不会因为发放这笔钱而增加大量政府工作人员,所以不会制造出一个“大政府”或者“福利国家”——美国人民最怕听这两个词了。总而言之,Yang提出的这个“全员基本收入”(Universal Basic Income)计划,能以不大的代价显著提升社会整体福祉,其经济角度的逻辑是相当严密可靠的。

但对于规模性、结构性失业之后大量劳动者应该干什么(即使有每月2千元的基本收入领着)这个问题,Yang的回答有些语焉不详。他认为人们可以更多地回归到信息时代之前的社区互助的生活与生产模式,可以有更多不借助现代自动化技术进行的劳动,邻里之间可以互相帮助、互通有无,在这样的劳动中找到人生的意义、完善自我。这个与马克思所说“上午打猎,下午捕鱼,傍晚从事畜牧,晚饭后从事批判”遥相呼应的愿景,至少Yang在论述它时,是缺乏坚实有力的论据支撑的。
这本书的作者Yang早年间曾致力于孵化初创企业。但后来他发现,大众创业消化不了结构性失业甩出来的劳动人口,万众创新更是没有那么多的新可以创,只是让原来有组织、有保障的劳动者打更多收入低、没有保障、劳动环境恶劣的零工而已。这也是促使他转变思想、倡议全民基本收入的原因。据说Yang可能在下一次美国总统竞选中参选。一位以“每月发你2千元”为口号的候选人能否赢得工业州的支持,还真是令人期待呢。
-
穷学IT(给侄女的一封信)
亲爱的侄女玥玥,
从上半年就想找时间和你深入谈谈,一直找不到合适的时间。我俩又都是内向的性格,面对面谈话也挺尴尬的,所以不如用文字的形式把我的想法写给你吧。
今天应该是新学期第一天吧?转眼你就上高三了。你父母对你未来的前途、尤其是应该选择什么专业,有很多担心,问到我的建议。我从自己有限的知识,能给你的建议就是:要学计算机相关专业,未来从事IT行业。
网上有种说法,叫“富学金融,穷学IT”。金融和IT是目前中国薪资最高的两个行业。金融专业是不是只有富家孩子才能学、才能搞出名堂,我也不太清楚,不过确实看到很多学金融毕业的孩子也不太好找工作,要靠父母拉到存款、卖出理财,或者因为父母的背景关系,才能在银行里有比较好的发展。可能全中国也只有IT行业,至少到目前为止,还是一个相对公平、相对开放、相对透明的行业,是一个穷人家的小孩不靠关系、不靠家底、不靠父母的帮衬、甚至自己不用溜须拍马,也可以得到比较高的薪资,甚至实现阶级跃迁的地方。
现在的大人们不太说“阶级”这个词了,他们有时候会说“阶层”。中国正在很快地变成一个阶层固化的社会,意思是,父母一辈的生活什么样,孩子一辈的生活大概也就是什么样,甚至更差,想过上比父母”高级“很多的生活,很难,而且正在变得越来越难。我俩的家境都不算好,我的父母、你的父母,都是老工人,不是什么富贵人家,所以阶层固化这事,对我们来说是件很糟糕的事。我幸运一点,2000年代初的时候,阶层固化还没有很严重,即便如此,我事后回想,现在能有一个比较好、比我父母好的生活状态,最主要的原因还是因为搞了IT这一行。
我预计到2023年,你走出大学校门的时候,中国很多行业很多职业会严重过剩,会有大量的人失业。原因跟IT有关:软件的自动化、人工智能,这些技术会取代人的工作。比如我父亲以前开跨省的大货车,这种职业可能很快就会被无人驾驶的货车取代掉,整个高速公路段不需要司机,货车自动驾驶,只有从高速公路出口转运到城市这一小段由司机来开。那么司机的人数和待遇,都会降低很多。甚至很多传统看起来很光鲜的职业,律师、医生、教师,都会受到IT技术的挤压。整个社会的趋势会变成,少数精英收益很高,大多数一般人压力越来越大、待遇越来越差。IT行业、特别是搞技术的职业,可能是唯一一个不太受技术挤压、反而因为技术发展对人才需求越来越旺盛的行业。
在一个人才需求旺盛的行业,才会有公平的竞争、对员工的重视、对女性的尊重,才会有普通人不靠背景不靠关系靠自己努力一步步上升的可能性。在阶层固化严重的行业、在人力过剩的行业,论资排辈苦熬日子已经算好的,你会看到更多的关系户、更多的拼爹、更多的溜须拍马、更多的人情世故、甚至是更多的职场性骚扰。我知道你不太擅长数学,但是更希望你不用被迫变得擅长处理这些破事。所以我希望你能学计算机、搞IT。
可能你今天会觉得,搞计算机、编程,这些事情听起来太高深了,太难了,太不适合你这么一个秀气的女孩做了。我想告诉你,这些都是扯淡的。成为一个合格的IT技术人员,凭技术能力给自己挣到一份不错的生活,需要的知识水平并不比其他行业更高,甚至还要低得多,因为这个行业太缺人了。你只要有好奇心、勤学苦练、把英文学好,你就能做到。而且这个行业几乎没有体力要求,可以说是最适合女孩的。我知道有些人会跟你说文秘、柜员之类的工作更适合女生,他们没有告诉你的是,这些职业薪水比较低,而且很容易被人工智能取代。IT行业、特别是技术岗位,可能是全社会男女最平等的高收入职业了。
总而言之,现在中国经济形势不好,未来可能会更糟。经济不好,阶层固化就会严重。在一个阶层固化的社会里,我现在观察,IT行业可能是唯一需求旺盛的行业。现在学计算机相关专业、未来从事IT行业的工作,可能是像你我这样的穷人家孩子唯一的翻身机会。大学四年,可能是你未来人生中最后一段可以享受低成本教育的时间、最后一次改变人生轨迹的机会,一定要慎重选择。
祝学习进步。表叔上。
-
动态代理的前世今生
(本文发表于《程序员》杂志2005年第1期,是我多年技术文章写作中难得的佳作,故此特意从杂志扫描文件转录为文字,以备散轶。)
文字写作有一个坏处在这里,斐多,在这一点上它很象图画。图画所描写的人物站在你面前,好像是活的,但是等到人们向他们提出问题,他们却板着尊严的面孔,一言不发。写的文章也是如此。你可以相信文字好像有知觉在说话,但是等你想向它们请教,请它们把某句所说的话解释明白一点,它们却只能复述原来的那同一套话。
——苏格拉底遭遇这种困扰的不仅有图画和文字。实际上在我们这个领域里,也有一些技术曾经或正在处于类似的遭遇这种困扰的不仅有图画和文字。实际上在我们这个领域里,也有一些技术曾经或正在处于类似的窘境:它们的发明者赋予了它们连篇累牍的文档,但这些文档终于——尴尬地——无法向它们的读者说清自己的功用。它们只能一遍遍地重复着那些晦涩的官样文章,让读者们大打哈欠。然后,直到某一天,仿如天启一般,一位阐释者出现了,惟有等他——而不是这技术的创造者——把这技术的用途解说得清清楚楚。人们才终于发现了这种新技术的价值。
这并非是天方夜谭。在Java语言中有一种名为动态代理(dynamic proxy)的技术,如今人们将它奉为天物,如果一个容器没有使用动态代理(或者更高级的代替物),简直就会立即被时代的潮流淘汰(梢后我们会看到这样的例子)。然而,动态代理技术原本是随J2SE 1.3于2000年发布的,为何要到两三年之后才突然变得炙手可热,这里发生了怎样曲折的故事?今天,笔者不揣冒昧,想带领读者来了解动态代理背后的故事。
什么是动态代理
在JDK 1.4.2的JavaDoc文档中,我们找到了
java.lang.reflect.Proxy类,然后就是一篇长长的介绍,其中这样写着:动态代理类(dynamic proxy class,下文简称代理类)是这样的一个类:可以在运行时、在创建这个类的时候才指定它所实现的接口,这些被代理类实砚的接口被称为动态接口(dynamic interface)。代理类的实例被称为代理实例(proxy instance)。每个代理实例都有一个对应的调用处理器(invocation handler)对象,该对象实现
java.lang.reflect.InvocationHandler接口。当用户通过代理接口调用代理实例的方法时,该方法调用会被分发到该实例对应的调用处理器的invoke()方法,同时传入动态接口、代表被调用方法的java.lang.reflect.Method对象、以及代表方法调用参数的一个对象数组。调用处理器可以在invoke()方法中对接收到的方法调用进行相应的处理,该方法返回的结果应该是代理实例被调用得到的结果。你明白这是怎么回事了吗?噢,不用感到惭愧,即便是当我翻译这段文字时,我都很难读懂它到底想说什么。还好旁边就有一个例子。假如我们有一个接口
Foo:public interface Foo { void doSomething(); }你就可以直接创建一个实现了
Foo接口的对象实例,而不必为它创建一个实现类:InvocationHandler handler=new MyInvocationHandler(); Class proxyClass = Proxy.getProxytClass( Foo.class.getClassLoader(), new Class[]{ Foo.class }); Foo f = (Foo) proxyClass, getConstructor(new Class[] { InvocationHandler.class }). newInstance(new Object[] { handler }); f.doSomething();当然,你也注意到了,这里有一个新的类:
MyInvocationHandler,这就是与动态代理对应的调用处理器。毕竞,我们总得有一个地方放置真正的实现逻辑吧。这个类的实现如下:public class MyInvocationHandler implements InvocationHandler { public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { System.Out.println("Hello!”); return null; } }把这段程序运行起来,控制台上就会输出
Hello!字样。实际上,我们通常会把一个具体实现类的实例传给调用处理器,然后把具体业务的实现委派给这个对象去完成。private Object _target; public MyInvocationHandler(Object target) { _target = target; }然后在
invoke()方法中委派_target对象处理实际的业务逻辑:private Object invoke(...) { return method.invoke(_target, args);当然使用者也必须做一些修改(
Foolmpl是一个实现了Foo接口的具体类):InvocationHandler handler = new MyInvocationHandler(new Foolmpl());那么,这个东西又有什么特别之处呢?请再仔细看代理
类的创建过程,尤其是getProxyClass()方法的第二个参数:Class proxyClass = Proxy.getProxyClass( Foo.class.getClassLoader(),new Class[]{ Foo.class });这个参数传入的是代理类将要实现的所有接口。也就是说,我们的
MyInvocationHandler不仅可以用于创建Foo接口的实例,同样可以创建其他任何接口的实例。再看看创建代理实例时传入的第三个参数,这是一个MyInvocationHandler的实例,我们也可以在运行时改变这个实例内部包含的实现对象(即_target对象)。现在我们可以知道“动态代理”这个名字从何而来了,在《设计模式》书中这样写着:Proxy(代理):对象结构型模式
意图:为其他对象提供一种代理以控制对这个对象的访问。
别名:Surrogate(替身)在这里,被“控制访问”的对象(即
_target对象)可以在运行时改变,需要控制的接口可以在运行时改变,控制的方式(即InvocationHandler的具体实现)也可以在运行时改变。所以在这个代理模式中,代理者和被代理者的关系是完全动态的,这就是“动态代理”名称的由来。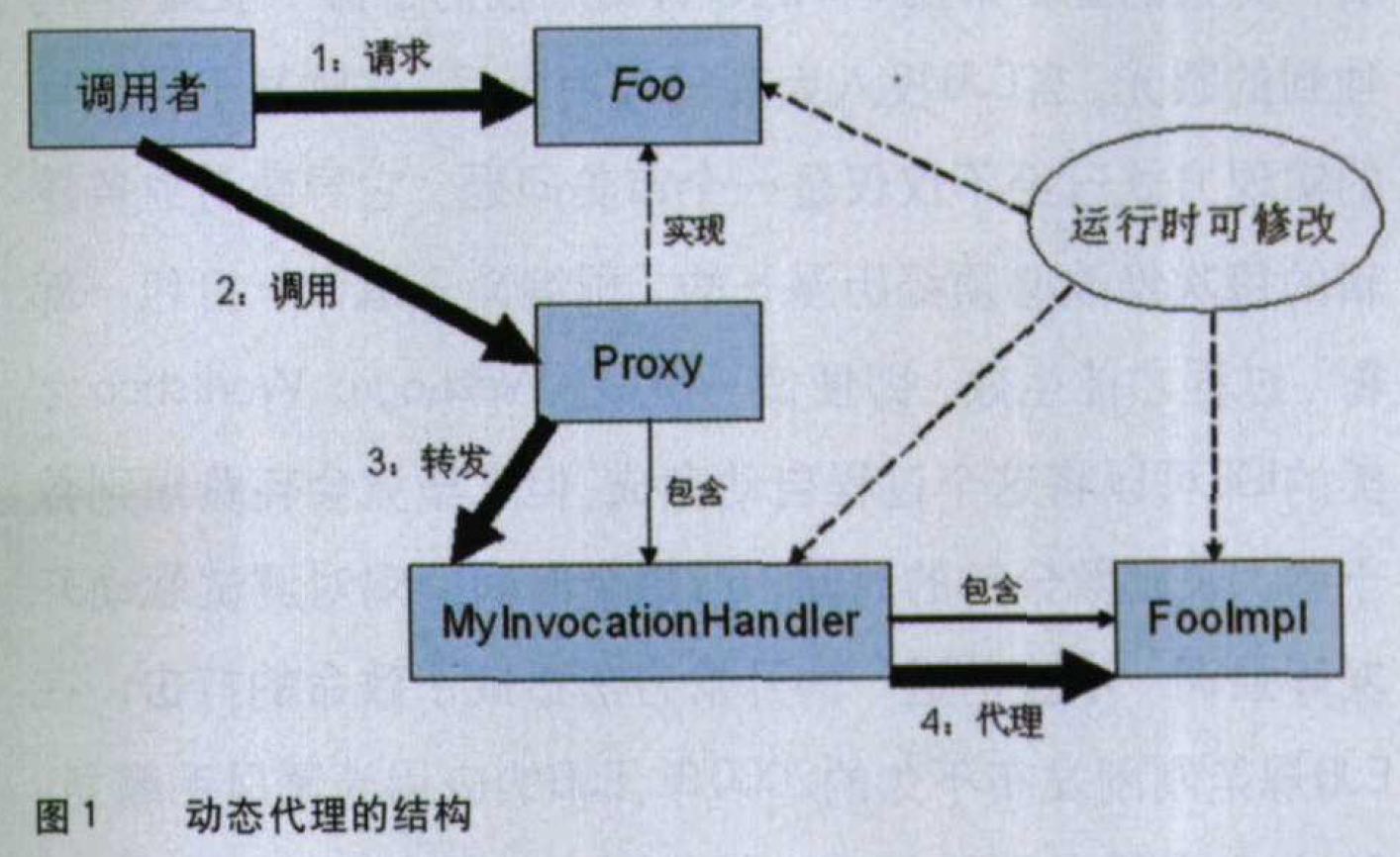
RMI的故事
也许你要说了:“好吧,我现在知道动态代理是怎么回事。可是它有什么用呢?”在2000年,刚拿到JDK 1.3的很多人都发出了同样的问题,其中就包括有“Java神童”之称的Rickard Oberg。当时Oberg正在设计JBoss的EJB容器——准确说是EJB容器中的RMI部分。我们都知道,如果一个EJB实现了本地接口,对它的调用将是普通Java方法调用;而如果它实现了远程接口,对它的调用就会变成RMI远程调用。从Sun的参考实现开始。绝大多数EJB容器(包括IBM WebSphere、BEA WebLogic等业界领先的产品)都采用了预编译的做法:首先根据业务代码生成对应的RMI skeleton,然后把 skeleton和业务代码一起编译,由容器在运行时将方法调用分发给合适的skeleton去执行。
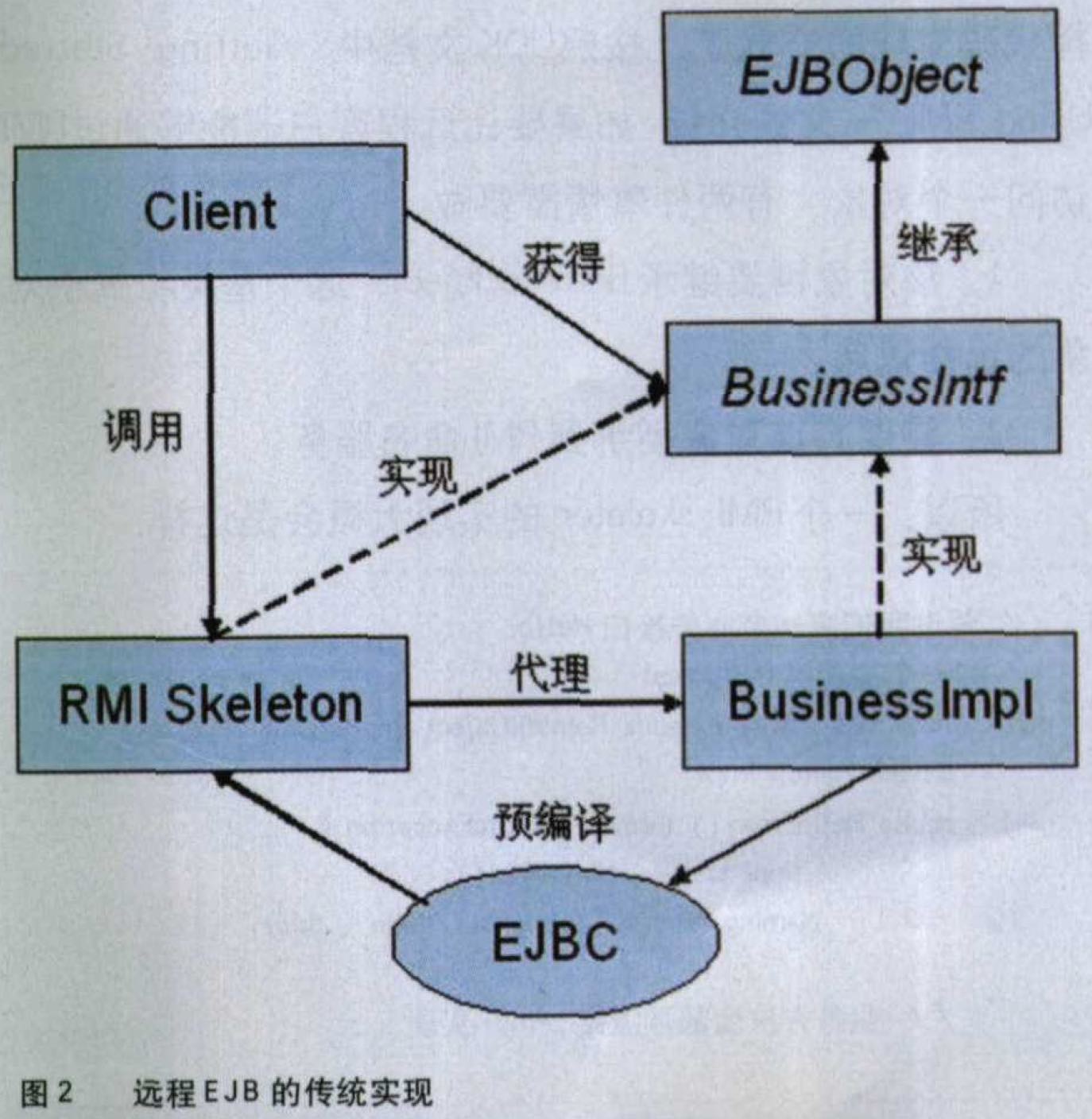
但是在Oberg敏锐而又挑剔的眼里,这种传统的实现方式是极度缺乏美感的。既然所有的远程EJB都必须提供RMI访问的途径,既然这种途径本身是与业务逻辑毫无关系的,那么凭直觉,这种“RMI访问的途径”就应该是一个单独的模块,而不是为每个EJB分别生成一份这样的代码。几年以后,当我们重新审视EJB的设计时,我们不得不敬佩Oberg独到的眼光。当EJB投入大规模应用之后,这种基于预编译的实现方式已经不仅仅是一个审美问题。它导致对业务逻辑的每次修改必须经历漫长的“预编译—编译—打包—部署”过程才能生效,即便像WSAD、 WebLogic Workshop之类的IDE可以将这个过程自动完成,但它毕竞会耗费短则数十秒、长则数分钟的时间,而这个时间间隔对测试驱动开发等强调“小步前进”的开发方法造成了致命的打击。在EJB规范刚刚发布不久的2000年,EJB的应用尚属凤毛麟角,Oberg完全凭直觉和审美就察觉了这种实现方式的缺陷,让我们不得不相信:很多时候具有美感的技术就是好的技术。当然,这是题外话了。
但是,要把“RMI访问的途径”抽象到一个单独的模块中并不是一件容易的事情,否则别的容器实现者也不会选择代码生成的方式了。按照JDK文档中“Getting Started Using RMI”一文的介绍,如果要让远程客户端能够通过RMI访问一个对象,有两件事情需要做:
- 该对象需要继承
RemoteObject,这个基类将提供对象的远程语意。 - 需要将该对象捆绑到RMI命名服务。
所以,一个RMI skeleton的实现大概会是这样:
// 假设我们有一个业务接口Hello // 和一个实现类HelloImpl public class HelloProxy extends RemoteObject implements Hello { private Hello _impl; public HelloProxy() throws RemoteException { _impl = new Hellolmpl(); Naming.rebind("//myhost/hello", this); } // 业务方法全部委派给_impl实现 }可以看到,尽管各个RMI skeleton的实现非常相似,但它们有一个最大的差异:它们必须实现不同的业务接口。熟悉C++的读者或许会说,如果有泛型(generic)技术,这个问题就不成问题了:我们可以设计一个
RMIProxy泛型类,并把Hello接口作为类型参数传入。话是没错,但别忘了,我们现在身处2000年,J2SE 1.3才刚刚发布,拥有泛型技术的J2SE 1.5自然不能为我们所用了。就为了获得实现不同业务接口的skeleton,EJB的实现者们才不得不选择了代码生成的手段。于是,这里的问题就集中为一个:如何创建这样一个代理类:它的实例可以实现任意的业务接口,并且可以在运行时决定一个实例究竟实现哪个业务接口。
啊哈,你开心地说,这不正是动态代理能提供的吗?2000年9月,Rickard Oberg也有同样的欣喜若狂:他突然发现,原来JDK 1.3提供的这个叫动态代理的东西可以这样来用。剩下的事情就是按部就班地写程序了。最后,Oberg完成了这个优雅的EJB实现,也奠定了JBoss直到4.0版本之前没有改变的架构基础。这是全世界第一个基于动态代理机制的EJB实现,JBoss一向引以为傲的热发布能力很大程度上正是得利于这个优雅的架构。如果读者对Oberg的这个“尤里卡”式的发现有兴趣,不妨找出JBoss 3.x的源码,亲眼看看RMI这部分的实现。
作为XDoclet的作者,Rickard Oberg不应该被看作代码生成技术的反对者。然而,相比之下,他对动态代理的热情绵延数年不绝,对于XDoclet倒是疏于维护,似乎只当它是一个玩具,这又是为什么呢?沿着这个问题,我们又拉开了另一个故事的帷幕……
三位一体
完成了JBoss的核心实现之后,Oberg并没有停止思考。一方面,他深感EJB的繁复给开发者带来了巨大的不便,于是开发了一个名为“EJBDoclet”的工具。这个小工具可以根据业务代码中特定的JavaDoc注释生成部署描述符、Home对象实现类等文件,大大减轻了EJB开发者的负担。2001年初,EJBDoclet的beta版本甫一发布,便受到众多EJB开发者的青睐。然后,Oberg又对EJBDoclet的架构重新做了设计,赋予了它灵活的插件机制,让开发者们可以创建各种插件插入其中,从而支持其他用途的代码生成。2001年9月,Oberg将EJBDoclet改名为XDoclet,此时它不仅可以支持EJB代码生成,还支持Struts、JSP Taglib、WebWork、Apache-SOAP和JMX。时至今日,几乎凡是需要配置文件的地方,你都可以找到XDoclet的支持,XDoclet已经成了J2EE开发者工具箱里必不可少的一件利器。这是后话,按下不表。
另一方面,Oberg本人仍然坚信:代码生成(尤其是自动生成Java代码)是一种恶行——虽然或许是必要的恶行。作为Java编程的顶尖高手,他对于“Don’t Repeat Yourself”这句箴言的领悟比大多数人更深刻。于是他开始总结:有哪些事情是在不断重复做的?动态代理能不能对解决这些问题有所帮助?对于第一个问题,他很快找到了不少的答案,例如:
- 日志:如果需要记录所有方法的调用时间、传入参数、返回值,就必须编写大量的重复代码。
- 安全性检查:如果需要给业务方法加上基于角色的访问控制,就必须逐个方法修改。
- 事务管理:如果需要访问事务性资源(例如关系型数据库),必须在每个操作之前开启事务、操作结束之后提文或回滚事务。
这些问题有一个共同的特点:它们都分布在各个对象继承体系中,任何业务对象都可能需要它们;另一方面,它们又与具体的业务逻辑几乎没有关系。也就是说,它们纯粹是基础设施(infrastructure)功能。如果用经典的面向对象手段来解决这类基础设施问题,必须采用Template Method或类似的设计模式:业务对象实现特定的接口(或继承特定的基类),通过接口提供的回调接口提供基础设施服务。
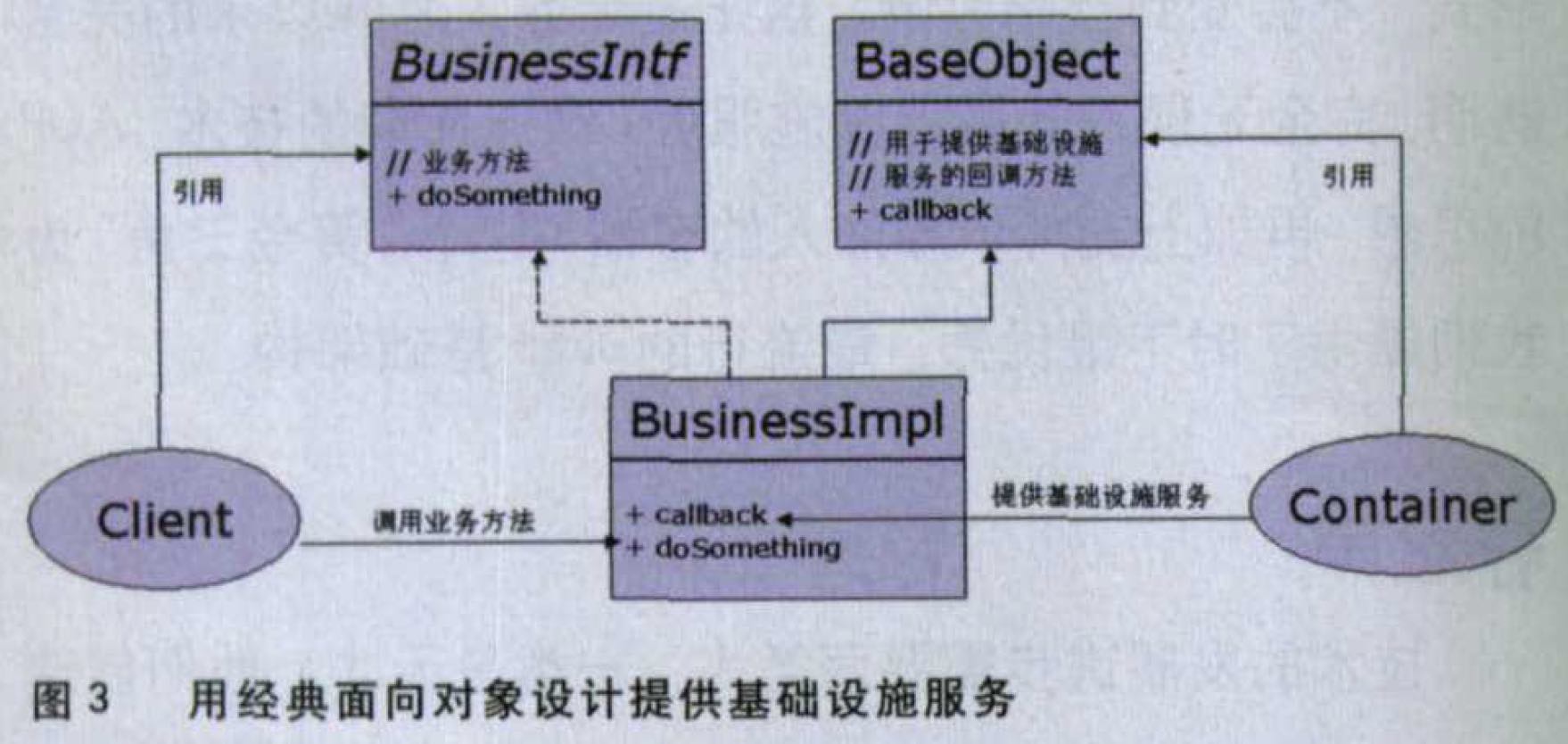
但这种设计方案有两个缺陷。其一,业务对象除了实现业务接口之外,还必须实现一个容器特有的接口(例如EJB容器规定的SessionBean接口)。甚至是继承容器特有的基类,这对业务对象造成了侵入,使它难以移植到别的应用环境中;其二,由于基础设施都是通过回调接口提供,所以“可以提供哪些基础设施服务”实际上是预先规定好的,不能根据需要定制——比如说,如果你突然需要统计每个业务方法执行的时间,那么很抱歉,容器提供的接口上没有相关的回调方法,所以无法提供这样的基础设施。这两个重大的缺陷正是导致EJB和Apache Avalon等经典容器最终无法满足需要而被淘汰的根本原因。
早在多年之前,一些来自高校和研究机构的学院派人士就提出:对于这种“横切”(crosscut)多个对象继承体系的基础设施问题,可以通过AOP (Aspect一Oriented Programming,面向方面编程)的手段来解决。1999年,帕洛阿尔托研究中心(PARC)的科学家们创造了一个叫做AspectJ的AOP实现品,并且在一些项目中用它来解决基础设施问题,取得了很好的效果。但是和大多数EJB容器一样,AspectJ也采用了代码生成的技术:程序员编写好业务代码和aspect代码之后,必须进行预编译,AspectJ的预编译器会把aspect织入业务逻辑之中,生成新的Java代码,然后才能编译运行。再一次地,代码生成显出了它的缺陷:由于每次修改业务代码之后都必须重新预编译,程序员的“开发—测试—重构”步伐不得不放慢;更糟的是,由于最终编译运行的是预编译之后生成的新代码,一旦有异常抛出,跟踪栈里的行号和业务代码完全不符,调试器也会因此而失效。这些问题使得AspectJ最终也仅仅是一个阳春白雪的实验室产品,没能在J2EE世界获得广泛的应用。
但AspectJ毕竟指出了一个方向、一种可能性,它的问题只在于代码生成。一位年轻人开始思索:如何不使用代码生成技术实现AOP。他就是Jon Tirsen,Rickard Oberg离开JBoss之后的挚友之一。Oberg是一个天才,但和所有的天才一样,他也有一个致命的毛病:他痛恨与智商低的人交流——如果对方跟不上他的节奏,他宁可选择缄默。所以,尽管用动态代理技术如此优雅地解决了EJB容器中RMI的问题,却并没有太多的人了解这一成就。好在Tirsen同样思维敏锐,他与Oberg的交流很快碰出了火花:只要将Oberg在JBoss里做的事抽象泛化,那就是一个基于动态代理的AOP实现。
既然方向已经明确,Tirsen立即投入了设计和实现的工作。他采用了“拦截器链”(Interceptor Chain)的体系结构:对于每个具有横切性质的问题,用一个拦截器(interceptor)来解决,然后把多个拦截器串成一条链;在一个动态代理的
InvocationHandler中拦截到所有的方法调用。就可以挨个执行链条上的每个拦截器。这样一来,不管有多少基础设施服务需要提供,也可以应付裕如了。很快,他就完成了这个产品,这就是Nanning框架——Tirsen曾到中国的广西旅游,旖旎的山水令他乐而忘返,所以他用了广西首府南宁的名字为自己的作品命名。2002年11月,Nanning发布了第一个版本。随后,由Jon Tirsen和Rickard Oberg牵头,一群AOP技术的先行者又成立了“AOP联盟”(AOP alliance)组织,制订了Java AOP的标准API。这样,aspect本身也可以在不同的AOP框架之间移植、复用,只要这些框架都支持这套标准。如今所有基于动态代理的开源AOP框架都实现了这套标准,说明Jon Tirsen选择的架构思路已经得到了同行的一致认可。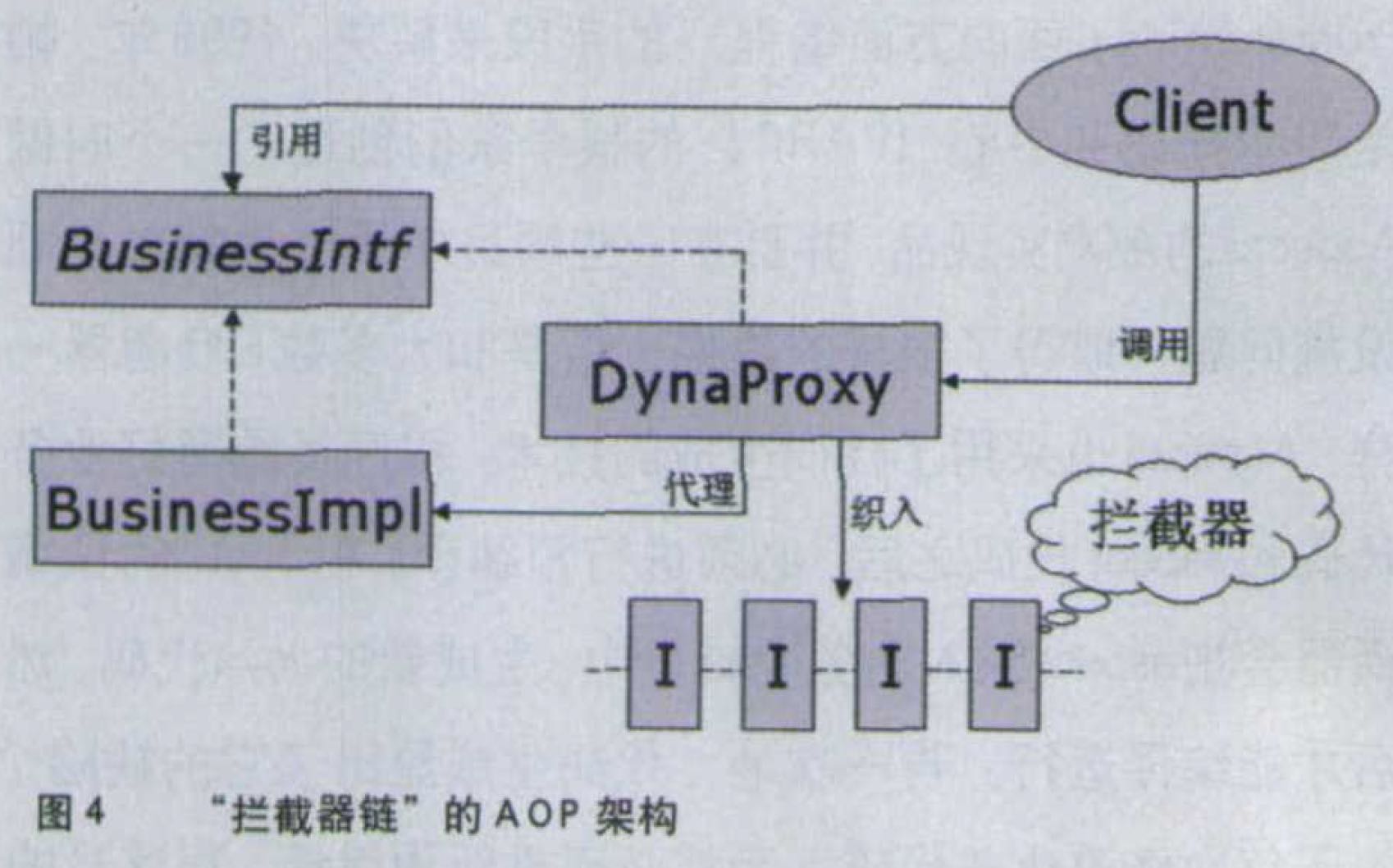
但这时的成果还不足以让Tirsen和Oberg满意,因为它的易用性还不够好。在2002年以前,几乎每个J2EE应用中都有大量的工厂(包括Service Locator),这是为了分离接口与实现、分离使用与创建,甚至有很多优秀的架构师声称:“没有大量工厂的应用不是好的应用。”如果要为这些应用引入AOP,势必要大范围修改工厂:即便是在新应用中引入AOP,也需要对工厂的实现方式做很多调整,从而丧失了AOP理想中的“透明性”——即:所有业务代码都不知晓AOP的存在,看起来,要想获得完全透明、完全无侵入的基础设施,这里似乎还缺了点什么。
最后的一块拼图很快就出现了。ThoughtWorks公司(也就是Martin Fowler的公司)的Paul Hammant和Aslak Hellesoy等几位员工在业余时间创建了一个开源项目,叫做PicoContainer——极其徽小的容器。这个容器可谓名副其实:它的全部源码只有区区20个类、数百行代码,甚至没有使用JDK之外的任何类库。可是,Tirsen甫一见它,立即为之倾倒,迫不及待地加入了它的开发团队,并把它推荐给好友Oberg,后者也同样如获至宝,在自己的blog上对它赞不绝口。
这个“小东西”的魅力究竟何在?在于它实现了后来被Martin Fowler称为“依赖注入”(Dependency Injection)的机制。简而言之,PicoContainer的核心理念可以提炼为两点:第一,使用者必须通过容器获得组件;第二,组件的创建、生命周期和依赖关系由容器全权负责。抛开别的好处不说,这样的容器能够提供一个全局唯一的对象获取点,实现Tirsen和Oberg希望的、“透明的”AOP也就有了下手之处。于是,Tirsen很快就把Nanning和PicoContainner(准确地说,是PicoContainer的姊妹项目,增加了XML配置等外围功能的NanoContainer)整合起来,得到了一个近乎完美的解决方案:事务管理、安全性检查、异常处理等基础设施都被实现为一个拦截器;一个业务组件是否需要拦截器,需要哪些拦截器都可以在配置文件中表达,不管业务代码还是用户代码都不需要任何修改,用Oberg的话来说,业务代码永远是这样:
public class BusinessImpl implements BusinessIntf { pubIic void doSomething() { //仅仅实现业务逻辑,不考虑基础设施 } }而用户代码则永远是这样:
public class Client { private BusinessIntf _business; // Type 3 IoC:构造子注入 public Client(BusinessIntf business) { _business = business } // 直接使用_business对象,不考虑基础设施 }这样一来,不管业务组件还是客户端都具有更好的可移植性,而且更容易测试:只要直接new出一个对象,通过构造子把它需要依赖的对象传入其中,就可以测试它的业务逻辑;如果需要改变依赖的对象,也只要在配置文件中修改一行即可;即使完全脱离了容器,用自制的工厂也可以轻松地装配这些对象。更重要的是,基础设施完全被隐匿到容器的背后了:不管有没有事务管理,不管有没有安全检查,业务代码和用户代码始终都是上面这样简单的形式,不会受到丝毫影响。这正是无数人梦寐以求的完全透明、完全无侵入的基础设施服务。动态代理的技术、AOP的思想,再加上支持依赖注入的容器,这个“黄金三角”为我们提供了时下最优秀最流行的J2EE基础架构。
春之声
技术的发展进步需要两类人:一类是天才,他们创造奇迹、拓展技术的疆域;另一类是传教士,他们读懂天才的思想,并传之于普罗大众。在J2EE的世界里Rickard Oberg是众望所归的天才,而Rod Johnson则是当仁不让的传教士。这位面容清瘦,已经谢顶的中年人是Servlet技术规范专家组的成员,那本厚达1400页的《J2EE编程指南》也有他贡献的章节。不过,Johnson真正名扬四海,还是因为他在2002年底出版的那本Expert One-on-One J2EE Design and Development,以及随后推出的Spring开源项目。公平地说,不管在J2EE Design and Development书中还是在Spring框架中,以至于在2004年初出版的Expert One-on-One J2EE Development without EJB中,Rod Johnson没有提出任何新思想、新技术——他所做的就是把天才们的发现归纳整理分门别类,写成寻常程序员也能看懂、能用上的书和框架。和我们这个故事有关的,AOP的种种用法——例如事务管理、remot ing、安全检查——都是经过Johnson的言传身教才飞入寻常百姓家,从这一点来说,Rod Johnson “J2EE传教士”的名号受之无愧。
既然Spring已经把AOP实现得非常易用,我们不妨来试着亲手编写一些AOP的程序。首先,假设在bean工厂配置文件中声明了这样的一个bean组件:
<bean id = “helloBean”class=”my.packge.Hellolmpl”/>使用这个bean的客户端代理如下:
BeanFactory factory = ...; Hello hello = (Hello) factory.getBean(“helloBean”); System.out.println(hello.sayHello());一切运行正常,控制台上打出了
Hello, World!的字样。现在,我们想要获得每个方法被调用的时间,正如前文所说,这是一个具有横切性质的基础设施问题,可以用一个拦截器来描述它:public class InvokeTimeInterceptor implements MethodInterceptor { public Object invoke(MethodInvocation invocation) throws Throwable { Date now = new Date(); System.out.printin( invocation.getMethod().getName() + " : " + now); return invocation.proceed(); } }MethodInterceptor是AOP联盟API中规定的一个用于方法调用拦截的拦截器接口,在它的invoke()方法中,已经把方法调用封装成方便的Methodlnvocation对象。只要经过适当的注册,被拦截对象的每次方法调用都会首先通过拦截器的invoke()方法。现在我们就来配置这个拦截器,Spring提供的ProxyFactoryBean可以将拦截器与业务组件结合起来:<bean name="timeInterceptor" Class="my.package.InvokeTimeInterceptor" /> <bean name="helloBean" class="my.package.ProxyFactoryBean"> <property name="proxylnterfaces"> <value>org.groller.dynamicproxy.Hello</value> </property> <property name="interceptorNames"> <value>timeInterceptor</value> </property> <property name="target"> <ref Iocal="helloBeanTarget"/> </property> </bean>请注意,为了不影响客户端的使用,我们把这个新的bean也命名为
helloBean,而原来的业务组件则被改名为helloBeanTarget,表示它是“被拦截的目标”。现在,我们再次运行客户端代码,控制台上出现了下列字样:sayHello : Sun Dec 12 13:02:06 CST 2004 Hello, World!
说明我们的拦截器已经生效了。用同样的方法,我们可以把任何拦截器施加在任何业务组件之上,从而提供灵活的基础设施服务。而且,对于常用的基础设施,Spring框架已经提供了更便利的代理工厂,例如事务管理可以通过
TransactionProxyFactoryBean获得,Hessian remoting可以通过HessianProxyFactoryBean获得。时至今日,J2EE架构师们已经一致同意:基础设施服务应该以AOP的形式提供,所以是否提供便利的AOP已经成为了挑选容器的重要条件之一。虽然动态AOP并非都是以动态代理技术实现,但其他实现技术(例如CGLIB)在原理上与动态代理都是一脉相通,所以完全可以说,正是动态代理技术的出现和发展,让整个J2EE世界的架构理念发生了根本性的变化,而Spring框架则是推动这场变革的一阵春风。尾声
时间走到2004年底,关于动态代理的故事到这里已经讲完了,但故事并没有结束。就在12月8日,当笔者采访“UML三友”之一的Ivar Jacobson时,他略微透漏了自己对AOP的全新认识。在Jacobson看来,AOP已经可以上升到方法学的高度,它与用例的结合将进发出更加耀眼的火花。大师的新作Aspect-Oriented Software Development with Use Case已经面世,我们即将看到AOP思想会给我们带来怎样的新惊喜。
很有趣地,每当想到AOP的眩目前景,每当看到AOP给我们带来的巨大变化,我总是禁不住暗想:如果没有2000年时Rickard Oberg对动态代理技术的顿悟,现在的AOP、乃至整个J2EE社群的技术潮流又会是什么样子呢?或许,这就是“文本”与“阐释者”之间宿命的渊源吧。
- 该对象需要继承
-
机器学习项目如何管理:看板
在前面的文章中我们看到,涉及机器学习、人工智能的项目,普遍地存在项目管理的困难。然后我介绍了针对这类项目如何设置合理的期望,并且深入分析了机器学习项目的工作内容。既然已经知道如何设置客户的期望、又知道可以做哪些事来逼近这个期望,那么围绕期望和动作进行任务的拆解、管理和可视化应该是顺理成章的。
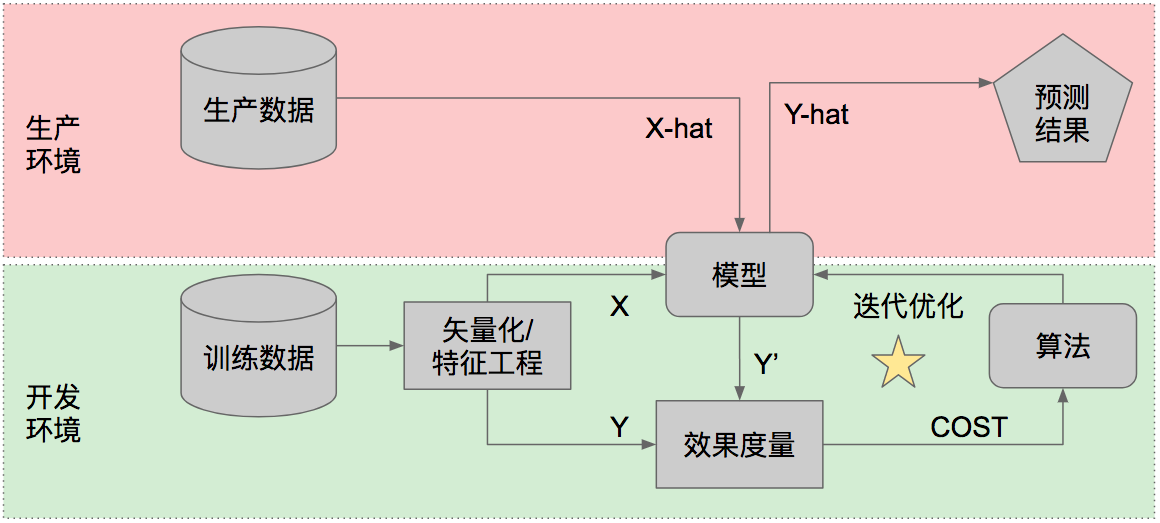
在前一篇文章中我们已经看到,一个机器学习项目涉及的三类九项工作内容当中,只有一项(“自行训练模型”,上图右下角标星星的部分)不是传统的软件开发任务。只有针对这项工作内容,我们需要新的任务拆解和管理方式,其他部分可以用标准的Scrum方法来处理。
对于“自行训练模型”过程中的具体任务,可以沿用学校里做实验的概念,将每次模型训练记录为一次“实验”。每次实验应该包含两个部分:
- 输入部分,即实验的初始状态:数据从哪里来;如何对原始数据加工;选取哪些参数;如何训练模型
- 输出部分,即实验的效果:模型是否准确描述训练集;模型是否overfit训练集;有多少false positive;有多少false negative
于是我们得到了一张“实验卡”,上半部分记录实验输入,下半部分记录实验输出。

把若干张实验卡放在一个看板上,就得到了可视化的实验管理墙。在项目启动时,首先制定一部分实验计划(以一批实验卡的形式),记录每个实验设计的输入部分。每做完一个实验,就在对应的实验卡上记录实验输出。在项目进展过程中,也可以不断增加新的实验卡。项目过程中,做实验的优先级由上一篇文章中介绍的“自行训练模型的流程”来判断:从一个简单的模型开始,首先尝试能降低Bias的实验,当Bias逼近期望时,再做降低Variance的实验。
作为项目管理者,对着这样一面实验看板墙,需要关注的信息有以下几个方面:
- 看产出:实验效果(Bias-Variance组合)是否逼近预期?接下来应该做哪些实验?
- 看计划:实验计划是否完备?是否考虑到各种可能的算法?是否考虑到各种数据来源?是否考虑到各种数据加工方式?
- 看进度:做实验的速度有多快?训练集获取是否耗时太长?模型训练是否耗时太长?是否需要优化训练算法?是否需要增加计算资源?是否需要提高数据流水线自动化水平?
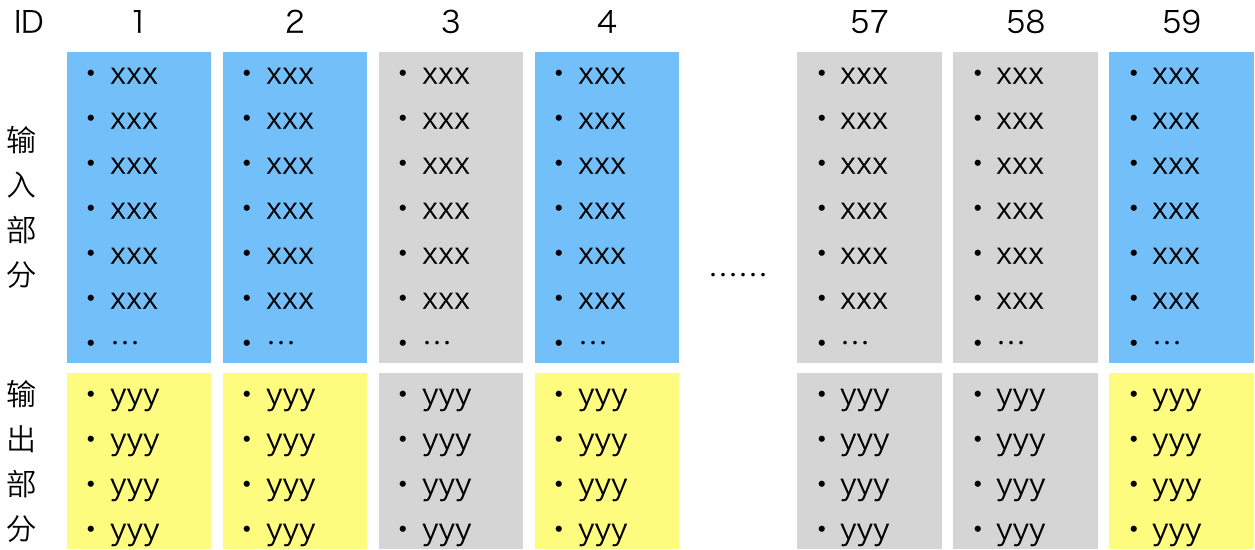
用这种方法,我们可以把看似神秘的机器学习项目拆解成独立、可讨论、有价值、可估计工作量、相对较小、可测试(INVEST)的实验卡,于是我们可以用Scrum方法来管理和度量围绕这些卡开展的工作。
-
区块链:原理和应用解读
(正值五四青年节之际,谨以此文送给有志青年们,祝大家多学技术,多写文章。)
区块链进入大众视野,是从比特币开始的——准确说,是从某些人因为比特币一夜暴富的传奇开始的。然而在随后的区块链热潮中,应该说大部分人是懵逼的。百度百科上,区块链的定义是这样:
区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。所谓共识机制是区块链系统中实现不同节点之间建立信任、获取权益的数学算法。
嗯,看得懂的人请举手。
一种如此难懂、绝大多数人不知道它究竟有何特点的技术,突然获得如此大的关注,怎么可能不被用于割韭菜、收智商税?(用区块链收智商税的终极形态,请看“傻逼链”。)但是我要说,区块链不仅是一种可以被掌握技术的资本家和骗子用来割韭菜的工具,它还是可以有一些靠谱的应用场景的。
到底什么是区块链?
很多人大概都听过某个版本的关于“什么是区块链”的解释。但我这个版本,经过验证,没有IT背景的土老财也能听懂,因此很可能是最适合广大人文社科有志青年来听的版本。
想象一个场景。某甲和某乙,两人合伙做生意。他们马上就有一个挑战:由谁来记账?这两个人必须互相信任,否则任何一个人记账,另一个人都可以怀疑他:你是否少记了一笔收入中饱私囊?这两个人如果各执一词,没有办法调解,所以他俩脆弱的信任如果破裂,生意就做不下去。
现在两个人的合伙里又加入了一个某丙,三个人,情况会好转吗?并不会。丙负责记账,甲照样可以怀疑:你和乙是不是串通一气的?你们是否少记收入自己私吞了?
那么大家是怎么解决这个信任危机的呢?办法有两个。第一个,是大家常见的办法:新来的丙是个持证的会计师,那么大家都可以信任他了。我们深究一下,为什么这种方式可行?为什么丙拿一本证书,就突然建立起了信任?原因当然是,丙如果被发现营私舞弊,他可能被吊销会计师资格,甚至可能身陷囹圄。这种风险太大,使得丙不太可能在常规的生意中这么做。而这种风险(换个角度,即围绕这本证书的信任)是由谁来背书的?答案是政府。政府用国家机器的暴力力量确保了,绝大多数情况下,会计师不会营私舞弊,会计师记的账是可以信任的。这个信任的背后,是枪在背书。
有了这个认知,我们可以去看看社会上绝大多数的信任机制,你会发现,几乎所有陌生人之间的契约和信任,都是国家机器、是枪在背书。为什么我拿钱可以买到面包?纸币的背后是国家的枪在保障,任何人一定认可它的交换价值。为什么我刷个信用卡也可以买到面包?招商银行的背后是央行在保障它的承兑能力,央行的背后是国家的枪。为什么我在淘宝上买的东西不满意就可以退货?因为货款在支付宝里,支付宝背后有银行保障它的承兑能力,最终背后还是国家的枪。
基于枪建立起来的信任机制足以满足大多数商业场景。但假如这个三人合伙做的不是合法生意,他们不想让国家机器知道这个生意,他们的信任危机又该如何解决呢?这里有第二种方法:三个人各记一本帐,分别都记录所有交易。如果帐对不上,以多数人相同的记录为准。当然,在三个人的情景下,这种机制能建立的信任还是很有限,因为你只要收买一个人就可以占到多数。但如果参与记账的有成百上千人,收买大多数的成本就会很高。随着参与记账的人越多,整套记账机制的可信度就越高。
这种“每个人都记一本账”的机制,就叫“分布式账本”。围绕着分布式账本建立的信任,不需要国家的枪背书,也不会因为任何一个人的腐化或者退出而破坏。所以我们说,这是一种“去中心化”的信任机制。
同时,虽然分布式账本是不需要国家的枪了,但分布式账本能实现,依赖于一个关键技术:所有的记账能迅速同步到所有账本。区块链就是实现分布式账本的关键技术。在这种技术中,每一次交易被记录为一“块”(block)数据,这样的“块”又彼此串联成一条“链”(chain),任何一个参与者都可以从任何一次交易的“块”牵出整条“链”,从而得到完整的分布式账本,这就是“区块链”(blockchain)这个名字的由来。
比特币的价值从何而来?
区块链的应用,最广为人知的无疑是比特币。但是只看各种正式的比特币介绍,你恐怕看不出为什么它有如此高的价值。比如说,一个正式的介绍可能会说,比特币是一种去中心的货币,它不需要国家为它的信用背书。但是,货币从来是用枪背书的,枪杆子越硬,货币就越值钱。一个不需要枪杆子背书的货币反而很值钱,这个逻辑是不通的。而这个不通的逻辑大家还能讲得这么热闹,恨不得把民主自由人权隐私全都放上来,说这个没有枪杆子背书的货币就应该值钱,这是一个很奇怪的现象。
当一个东西很值钱但是大多数人都看不懂它为什么很值钱,大概会是两种情况。第一,有人在搅浑水养韭菜。第二,有些关键信息没有说出来。而比特币的情况,两者皆是。我们不谈养韭菜的部分,谈谈那些没有说出来的关键信息是什么。
前面说了,分布式账本背书的去中心化信任机制,是在一个前提下有意义的:这个账本上记的账,参与交易的各方不想让国家机器知道。不然直接使用枪杆子背书的信任机制就好了。比如我们说比特币是一种货币(当然比特币实际上不是货币,但无所谓了,既然大家都说它是去中心化的货币,那就当它是货币好了),货币是用来买东西的,那么你买什么东西需要一种去中心化的、国家机器不插手的机制来建立信任呢?或者说,你买什么东西不能到淘宝去买(顺便叫卖家给你开张发票)呢?
毒品。枪支。儿童色情。人体器官。代孕。各种只能在黑市上交易的非法商品。
这就是比特币的拥护者们不肯/不愿/不能说出来的关键信息:比特币的价值,就是黑市的流动性。黑市对流动性的需求越大,比特币就会越值钱。(想炒币的有志青年请牢记这条基本价值法则。)
带着这个知识,再反观国内的区块链热潮,你就会明白为什么我说现在国内做区块链项目的有一个算一个全都是割韭菜收智商税的骗子。为什么呢?现在你想做某个事情,做这个事情你需要一种信任机制,而这种信任机制你不能靠国家机器的枪杆子来给你背书,这意味着什么?你敢把这件事拿到互联网上来宣传,你的网站上还打着工信部的备案编号,然后你跟我说你做的这件事非得有去中心化的信任机制才行,不觉得自相矛盾吗?
作为写作平台的区块链
还别说,我在国内还真的看到过靠谱的区块链应用。比如说,如果把党建信息承载在区块链上(而不是保存在一个数据库里),效果是什么呢?效果是,假如有一天中国共产党的执政党地位被反动派颠覆了,党组织被破坏,党员被清洗,党组织的活动可以立即转入地下,整个党建链上记录的党组织信息不可伪造、不可篡改、不可删除。万一有那一天,党建链就是传递革命薪火的火种。这事情现在已经有单位在做了,可见我党的先进性和忧患意识。
最近北大某同学的一篇文章又让我们看到了另一种靠谱的区块链应用。大家可以打开下面这个链接:
https://etherscan.io/tx/0x2d6a7b0f6adeff38423d4c62cd8b6ccb708ddad85da5d3d06756ad4d8a04a6a2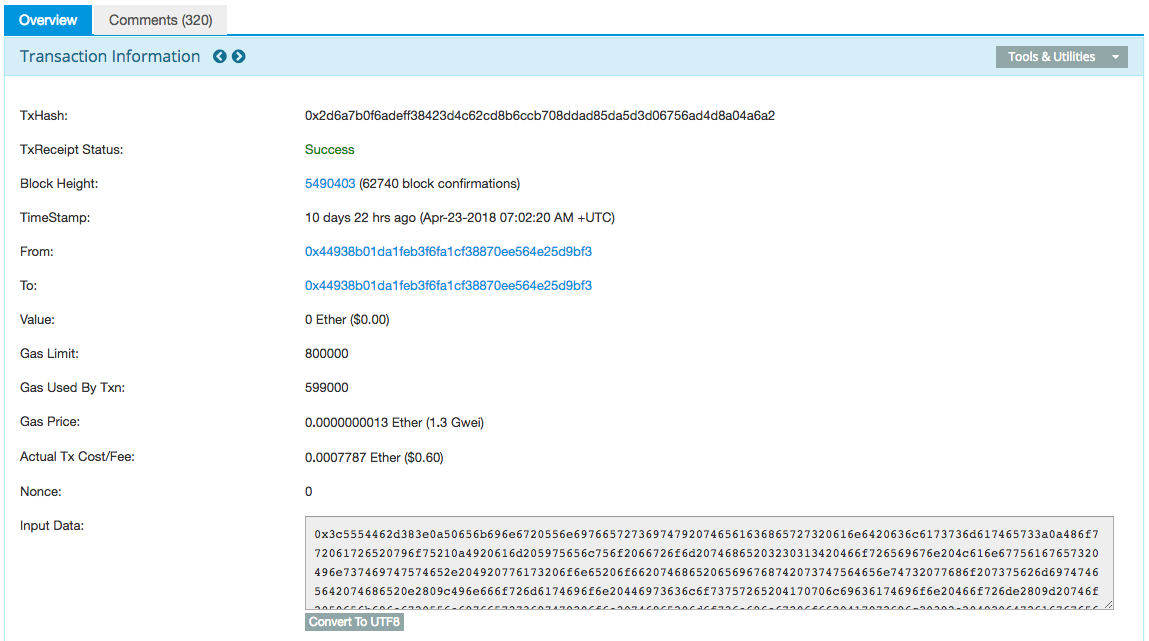
这是以太币(跟比特币相当的另一种去中心化数字货币)的一次交易记录。非常平淡的一次交易,这次交易本身的编号是“0x2d6a7b0f6adeff38423d4c62cd8b6ccb708ddad85da5d3d06756ad4d8a04a6a2”(以“0x”开头表示这是一个16进制的数字),它发生的时间是“Apr-23-2018 07:02:20 AM +UTC”,从编号“0x44938b01da1feb3f6fa1cf38870ee564e25d9bf3”的钱包转出,转入编号“0x44938b01da1feb3f6fa1cf38870ee564e25d9bf3”的钱包,转账的金额是“0 Ether ($0.00)”——对的,没真的打钱,不过没关系,金额为0也可以发起一次交易。所以真的是一次很无聊的交易。
这个交易真正有趣的部分,在于它挂载的数据,也就是下面的“Input Data”字段。区块链的每个“块”是有一定容量的,交易者可以把与这次交易相关的备注信息放进去,备注信息也会随交易块同步到所有的分布式账本。现在,在这个交易的“Input Data”字段,你可以看到一长串16进制数字:

如果你点击下面的“Convert To UTF8”按钮,你就会看到一篇熟悉的文章。我把这个探索的乐趣留给读者自己了,一定要去点哟。
这篇文章,现在已经同步到了全世界上千万个分布式账本。除非收买其中超过50%的人,否则这篇文章无法篡改、无法删除。也许你在豆瓣的转发会被删,也许这个查看以太币交易信息的网站会被墙,但是这篇文章会一直在那里,国外能看到,翻个墙也能看到,谁也删不掉,包括你自己也删不掉,哪怕你妈跪下来求你也删不掉。
所以,各位有志青年请记住,如果下次你想写一篇文章,并且你确定一定以及肯定绝对不会想删除这篇文章,不管是辅导员、校长、你妈、还是别的谁来求你,你都不会删除这篇文章,那么你可以把以太币、比特币之类的区块链平台用来做你的写作平台。你把文章发表到一次区块链交易的备注信息里,然后给大家发一个查看这次交易的链接。
要我说,这才是区块链技术正确的打开方式。
-
浅谈大数据平台基建的逻辑
这篇文章主要目的是面向初接触大数据的朋友简单介绍大数据平台基础建设所需要的各个模块以及缘由。
数据仓库和数据平台架构
按照Ralph Hughes的观点,企业数据仓库参考架构由下列几层构成:
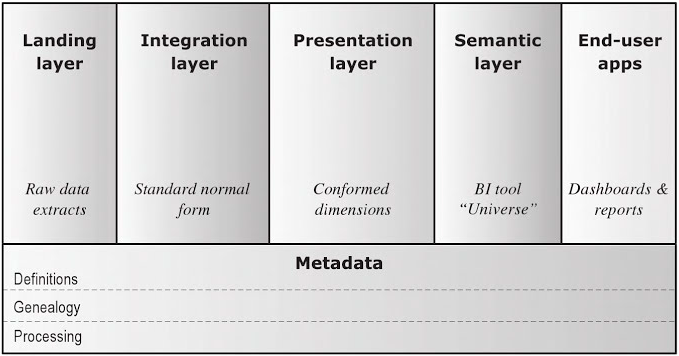
- 接入层(Landing):以和源系统相同的结构暂存原始数据。有时被称为“贴源层”或ODS。
- 整合层(Integration):持久存储整合后的企业数据,针对企业信息实体和业务事件建模,代表组织的“唯一真相来源”。有时被称为“数据仓库”。
- 表现层(Presentation):为满足最终用户的需求提供可消费的数据,针对商业智能和查询性能建模。有时被称为“数据集市”。
- 语义层(Semantic):提供数据的呈现形式和访问控制。例如某种报表工具。
- 终端用户应用(End-user applications):使用语义层的工具,将表现层数据最终呈现给用户,包括仪表板、报表、图表等多种形式。
- 元数据(Metadata):记录各层数据项的定义(Definitions)、血缘(Genealogy)、处理过程(Processing)。
把数据放到一起:数据湖
企业大数据平台的核心是把企业数据资产汇集一处的数据湖。ThoughtWorks的“数字平台战略”这样描述数据湖:
数据湖……的概念是:不对数据做提前的“优化”处理,而是直接把生数据存储在容易获得的、便宜的存储环境中;等有了具体的问题要回答时,再去组织和筛选数据,从中找出答案。按照ThoughtWorks技术雷达的定义,数据湖中的数据应该是不可修改(immutable)的。
来自不同数据源的“生”数据(接入层),和经过中间处理之后得到的整合层、表现层的数据模型,都会存储在数据湖里备用。
数据湖的实现通常建立在Hadoop生态上,可能直接存储在HDFS上,也可能存储在HBase或Hive上,也有用关系型数据库作为数据湖存储的可能存在。

接入原始数据:数据通道
企业大数据平台创造价值的基础是能把各种与业务有关的数据都接入到数据湖中,这就需要针对各种不同的数据源开发数据通道。数据接入的连接器(connector)通常是一个定时执行的任务,技术选型随数据源而定,有些项目采用定制开发的数据接入任务,也有些项目采用像Talend这样的套装工具。对于来自企业之外乃至互联网上的数据,可能需要编写爬虫。
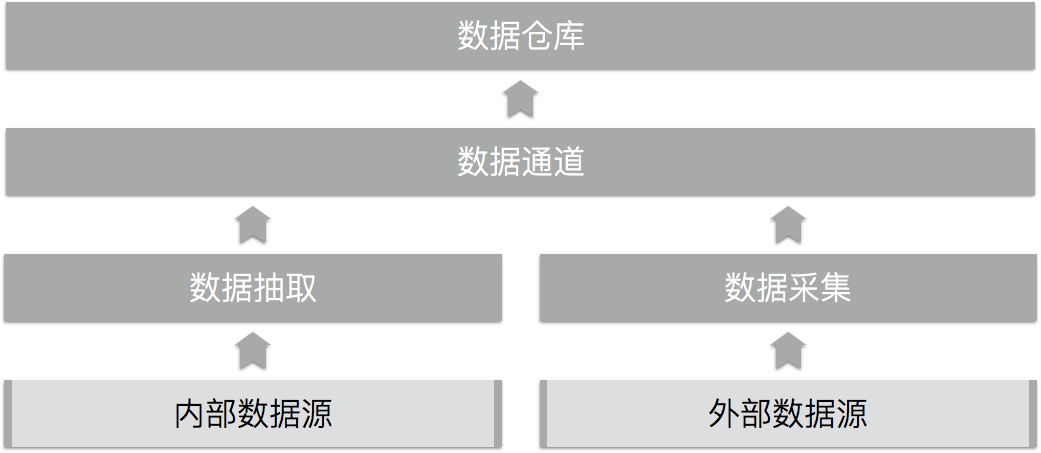
数据加工处理:数据流水线
在数据湖内部,数据会经过“接入层 => 整合层 => 表现层”的加工处理链,逐步变成用户可用的形式。其中每一层的加工处理,至少包含ETL(提取-转换-装载)、指标计算、异常检测、数据质量管理等工作,还可能对数据进行语义标签、分类预测等更深入的操作。
数据流水线的技术选型主要分为流式数据和批量数据两大类。在Hadoop生态中,Spark常被用于批量数据处理,Kafka和Spark Streaming的组合常被用于流式数据处理。

面向业务领域:数据集市
整合层存放了整个企业的数据,并且以规范化的、巨细靡遗的形式(例如Data Vault)对数据建模。表现层则与之不同:数据集市中的数据是针对业务应用领域选择出来的,并且建模形式更方便查询(例如宽表)。数据集市的技术选型也是为了查询的便利,例如采用ElasticSearch或关系型数据库,因为这些工具都支持很完备的查询功能,而且用户也非常熟悉。

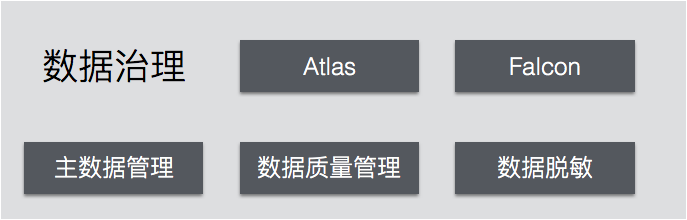
保障数据质量:数据治理
在实施数据湖的时候,有一种常见的反模式:企业有了一个名义上的数据湖(例如一个非常大的HDFS),但是数据只进不出,成了“数据泥沼”(或数据墓地)。造成这种现象的原因之一,就是因为缺乏必要的数据治理:数据缺乏一致性、数据质量不佳,导致用户无法从数据中获得可靠的洞察。
数据治理的基本工作包括了数据脱敏、数据质量管理、主数据管理等。Atlas、Falcon等工具提供了数据治理的技术能力。
探索未知:数据实验室
数据自服务能力的一大亮点是鼓励小型的、全功能的团队自行从数据中获得洞察。为了形成从数据到洞察的快速响应循环,业务团队需要对整合层甚至接入层的数据做快速的探索和实验,而不是先完成接入-整合-表现的整个数据处理链。数据实验室提供模型管理和数据沙箱的能力,让业务团队能用Python、Java等通用编程语言快速展开数据探索和实验。PyTorch、Jupyter、Pandas等工具提供了便捷的途径来搭建数据实验室。

供给应用:数据商店
确定要提供给业务团队使用的数据,就可以进入数据商店,包装成数据产品或服务的形式供应出来。基础的形态可以是直接对外提供数据(通过数据库同步、事件订阅、文件服务等形式),在微服务语境下我们更鼓励的方式是以API的形式对外暴露数据服务,更进一步的想法可能是以SaaS服务的形式对外提供。例如Forbes认为以下几种数据服务已经具有较高的成熟度和接受度:
- 用于benchmark的数据
- 用于推荐系统的数据
- 用于预测的数据

大数据平台的全貌
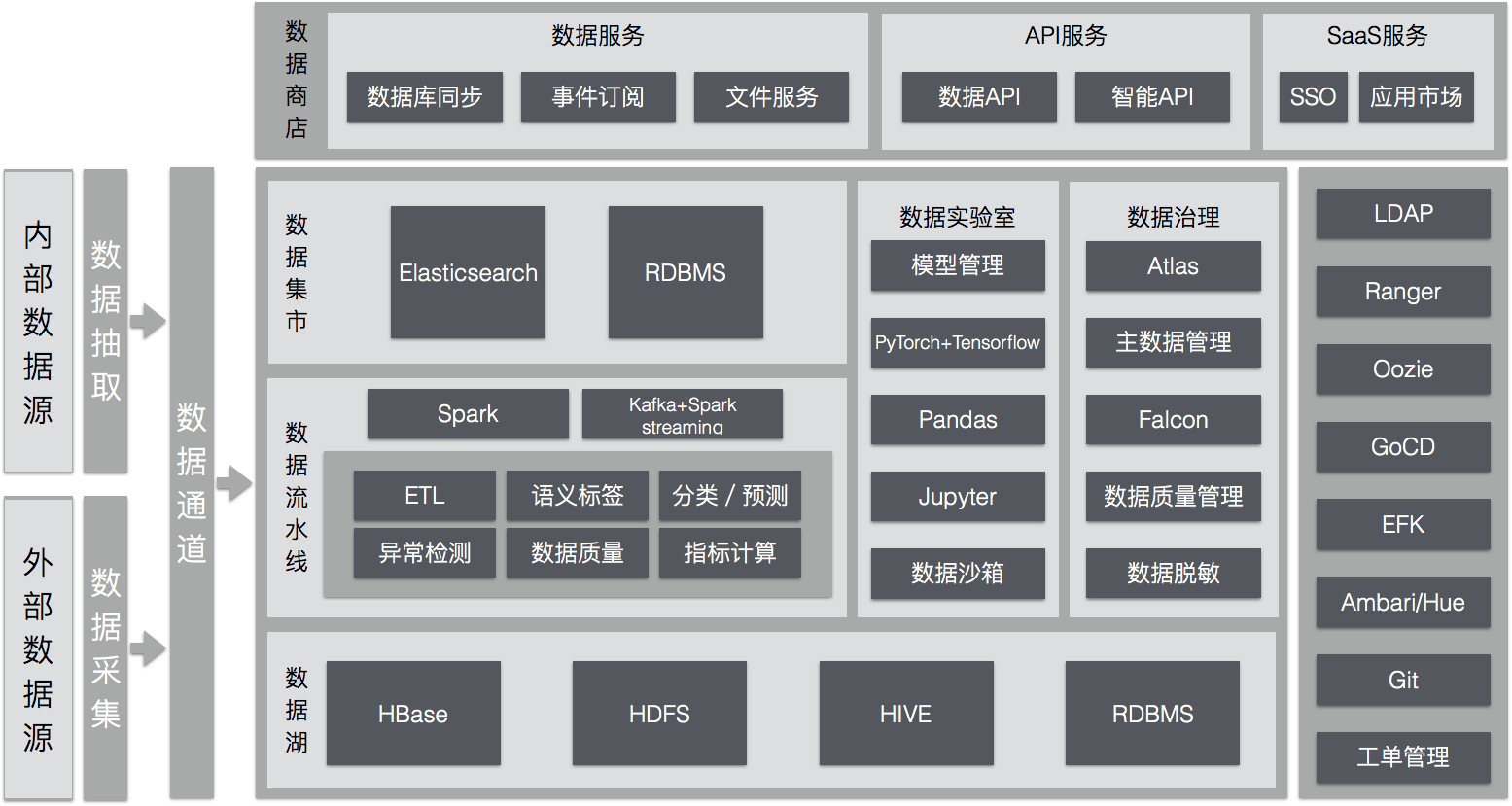
到这里我们已经看到了大数据平台各个组件的来由和形状:以数据湖为中心,由数据通道接入原始数据,经过数据流水线的加工处理,根据业务需求进入不同的数据集市,业务用户或是通过数据实验室探索、或是从数据商店获得自己需要的服务,整个过程接受数据质量和一致性的治理。再加上系统监控、日志管理、身份认证、任务调度、配置管理、项目管理、持续交付等通用的能力,我们就看到了一个企业级大数据平台的全貌。
-
敏捷在中国这十五年
题记:2002年3月,《程序员》杂志发表了《极限编程》技术专题。以此为标记,敏捷进入中国已经十六年了。这篇文章是我去年为《程序员》写的年终回顾文章,发表于《程序员》2018年第1期。
时至岁末,各种年度调查报告渐次登台。其中我注意到云栖社区发布的《2017开发者调查报告》中有一项数据:45.6%软件开发者所在的组织采用了敏捷软件开发方法,在各种开发方法学中位居第一。这个数字又让我联想起,CSDN在年初发布的《2016年度中国软件开发者白皮书》中提到,64%的受访企业采用了敏捷项目管理工具。虽然之前也曾经看到某些调查声称“98%的企业计划采用Scrum”,但我对于这些调查的采样范围一向存疑。云栖社区与CSDN的这两个报告,在我看来客观而坚实地明确了敏捷在当今IT行业的主流地位。
作为站在传统企业数字化前沿的咨询师,来自各个行业甲方的动向也给我同样的感知。在电信行业,浙江移动大张旗鼓地开展敏捷转型与DevOps体系建设,并与咨询师结对公开演讲,介绍自己的转型经验。在金融行业,渣打银行的敏捷转型已经进行数年,汇丰银行以敏捷理念构建他们位于西安的研发中心,招商银行的CIO陈坤德在金融科技峰会中正面提出“银行必须敏捷化”,新成立的民营互联网银行更是从诞生第一天就把短迭代、自动化、持续交付等敏捷实践植入在基因深处。在汽车行业,7月发布的《汽车销售管理办法》打破了传统4S店对销售渠道的垄断,乘用车主机厂纷纷上马在线营销或销售系统,欲与已在地平线露头的汽车电商一争高下,短迭代、微服务、持续交付同样是他们在数字化渠道建设中的主题词。在航空行业,海南航空旗下的科技集团把自己转型成PaaS云供应商,组织文化、工作方式全面对标互联网企业,敏捷岛、看板、信息可视化等硬件设施已经成为研发团队标配。看着各行业头部企业的动向,我感到现在已经可以放心地说:敏捷,已然成为不可逆转的时代大潮。
这股大潮在中国最初的涓滴潜流,大约要追溯到十五年前。2001、2002年,彼此互不相识的几组人,几乎不约而同地向中文世界引进与敏捷相关的资料。《程序员》杂志在2001年12月专栏介绍重构、2002年3月专栏介绍极限编程,是中文出版物中有案可查的最早的先行者。同在2002年,北京软件过程改进组织(PKSPIN)的成员唐东铭向人民邮电出版社推荐了Kent Beck的《解析极限编程》,后来这一套《极限编程丛书》于2002年10月出版。到2003年,《软件研发》杂志的创刊号大篇幅介绍敏捷方法,《重构》、《敏捷软件开发》、《自适应软件开发》等一系列重量级著作引进。今日的风起云涌,即肇始于当年的青萍之末。
饶有趣味的是,唐东铭本人在后来的职业生涯中一直没有机会亲身经历一个敏捷的项目。他的经历,映出了行业的发展历程。敏捷所强调的快速迭代、持续交付,对于植根政府和大企业内部信息化、仰赖“十二金”工程哺育的尚处幼年的中国软件行业而言,是太过超前了。时至2006年,在第十届国际软件博览会上,Martin Fowler做了关于敏捷方法的主题演讲,台下报以他的是困惑的眼神与尴尬的沉默。语言固然是尚未全面与国际接轨的中国软件业理解Fowler演讲的阻碍之一,更大的鸿沟还是在于观念与意识。对于其时的行业环境与技术环境而言,每两周一次迭代、每次迭代发布上线给用户使用,既不可能、也不必要。中国的IT业还没有做好迎接敏捷的准备。
决定性的转机发生在2008年前后。通信市场的争夺日趋白热化,4G相关产品的研发已经从原来先有规范后有产品,变成了规范产品同步进行,并且运营商也开始要求越来越多的定制功能。这种竞争态势,使各家大厂把应对需求变化、缩短交付周期放上了研发能力的优先级。从2005年底,诺基亚在杭州的研发中心已经开始试点敏捷,并把试点的成果带到了2006年与西门子合资的新公司里。2008年,诺西多条产品线开始大面积推广敏捷。同在2008年,爱立信也在大范围实施敏捷,将传统的功能团队转变为特性团队,用Scrum方法运作项目,并引入了持续集成实践。华为在印度的团队于2006年小规模试点敏捷,总部得知这一经验后于2007年开启一系列试点项目,并于2009年开始全面推广,特性团队、双周迭代、故事墙、持续集成等实践切实落到了基层。2010年落成的华为南京、上海两个新基地,都大量采用开放式办公区、敏捷岛的格局。在BAT气候大成之前,通信大厂是中国技术人才的重要源泉,这几家公司培养出的大量优秀敏捷教练与持续集成专家,为后来敏捷在行业里的广泛传播起到了推波助澜的关键作用。
互联网大厂的敏捷起步也并非一帆风顺。2009年,百度把握住谷歌退出中国市场的机遇,全面对标谷歌,包括工程师的工作方式。从单一主干开发模式切入,百度大幅提高了研发过程中的自动化程度,把产品发布周期从几个月一次缩短到了每周一次发布。迟至2012年,腾讯某些产品还只能做到两三个月发布一次,通过模块解耦、提升自动化水平、拆分特性团队、持续集成等实践,得以逐步缩短发布周期,达到了每天能发布两个可用版本的水平。
不过互联网大厂毕竟身处在时代大潮的前沿,时刻接触海量用户真实的行为反馈,以及每一点转化率提升带来的直接经济效益,使他们有直接的动力不断缩短发布周期。大野耐一强调的“湖水与岩石”理论在他们这里得到了淋漓尽致的发挥:发布周期从几个月缩短到一两周,可以靠组织和管理的改变;从一两周缩短到一两天、甚至一天发布若干次,必然要靠技术和平台的积累。BAT自不待言,美团作为二线互联网大厂,也把技术视为自身核心竞争力。对技术人员的尊重不仅体现在管理技术双线并行的职业路径上,也体现在开放、平等、追求卓越的文化氛围上。对技术的重视带来的反哺,则是平台实力的大幅提升。借由高效的数字平台赋能,领先的互联网团队已经超越了“敏捷”的范畴,开发人员无需刻意考虑敏捷的实践,眼前的数据和背后的平台已经驱动着他们自然地按照极短的发布周期不断演进产品。
当互联网大厂以这样的高节奏从线上往线下席卷而来,各个行业的CIO们纷纷上马敏捷,看起来更像是在BAT收割之前的末路狂奔。已经被驱动起来的金融、汽车、零售行业,在一波与时间赛跑的敏捷浪潮究竟会剩下几家欢喜几家愁?有着大市场基数和高利润空间的教育行业,最近连续曝出令人不安的丑闻,这是否会成为政策放松管制、互联网竞争大举涌入的契机?医药行业树欲静而风不止,近有医药改革两票制全面触动流通环节即有利益、阿里健康倒逼医院改革,远处还有政府依托腾讯建设国家级医疗人工智能平台的愿景,医药行业的数字化、互联网化转型何时会进入快车道?航空行业谋求用数字化拉升资产效率,从民航维修、机场运营,到顾客体验、航线收益,再到搭建云生态平台,对未知场景、未知需求的快速感知和响应能力何时会排上航空业IT的优先级?这些可能都是我们在未来一两年内就会看到答案的事。
作为中国敏捷十五年发展历程的亲历者与推动者,透过敏捷被引进中国、被推介、被传播、被漠视、被抗拒、被接纳、被推崇、被转变、被淡化的过程,我看到了整个中国IT行业、乃至中国经济发展的缩影。今天敏捷成为最为广泛采纳的软件开发方法,背后折射出的是IT在国民经济生活中的地位提升、是技术人员从外包码农到企业核心竞争力的地位提升、更是中国经济在全球经济中的地位提升。过去十五年,来自美国的敏捷软件开发方法指导了中国的IT行业;未来,中国的IT行业需要什么方法来指导,这个问题可能要靠我们自己来回答了。
-
数字化企业的实验基础设施
在前文中我们说到,传统企业在逐步建设自己的数字平台过程中,需要抓住交付基础设施、API和架构治理、数据自服务、创新实验基础设施和监控体系、用户触点技术这五个支柱。今天我们讨论的主题是数字平台战略的第四个支柱“实验基础设施”,看看一个倡导消除摩擦、建设生态、推动创新的数字化平台如何赋能快速、有针对性的商业实验。
DPS全局观
- 概述:什么是数字平台战略
- 第一支柱:数字化企业的交付基础设施
- 第二支柱:数字化企业的API架构治理
- 第三支柱:数字化企业的数据自服务
- 第五支柱:数字化平台中的客户触点技术
什么是实验基础设施
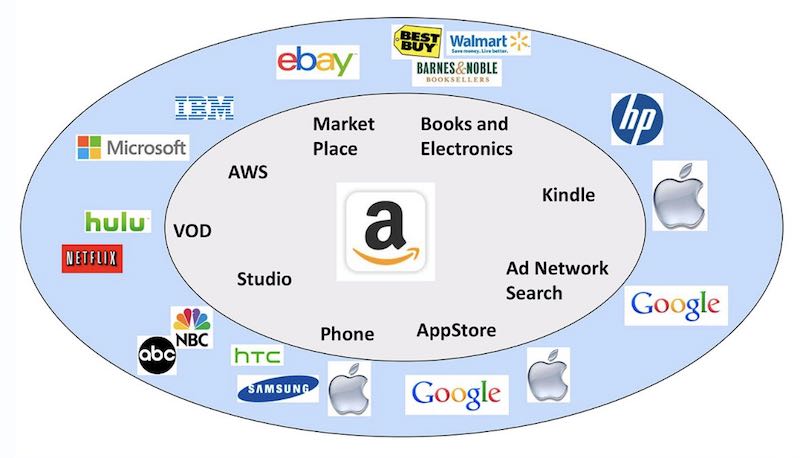
作为数字化企业的代表,亚马逊是众多怀揣数字化梦想的企业学习的榜样。今天的亚马逊,在零售、广告、消费电子终端、应用商店、云服务等多个领域与各领域的领先企业竞争。更可怕的是,除了丰富的业务线,亚马逊还有Dash Button、Echo、Prime Air、AWS等大量创新。最可怕的是,据AWS的CEO说,除了这些大家知道的、获得了一定成功的创新项目,还有更多创新项目失败了——而亚马逊认为完全OK。亚马逊强大的创新能力,背后体现的是更为强大的快速实验、快速学习、快速调整的能力。缺少这种能力,就算把亚马逊的产品和模式摆在面前照抄,也无法跟上它不断创新的步伐。
为了支撑数字系统的快速实验、快速学习、快速调整,需要在快速交付基础设施与数据自服务的基础上再考虑下列问题:
- 需要从多种来源采集关于系统、关于顾客的数据。
- 需要根据业务目标在系统中埋设监控点,并及时把监控结果可视化呈现给业务用户。
- 为了降低实验试错的风险,在把新版本发布给全部用户之前,应该以金丝雀发布的形式首先发布给一小部分用户,确保新版本不造成重大损害。
- 系统需要支持功能切换开关(toggle),允许团队在不修改代码的前提下改变系统的行为。
- 用路由技术支持蓝-绿部署和A/B测试,方可高效地开展受控实验。
实验基础设施详解
数字平台中的实验基础设施由以下特性共同支撑。
数据采集
精益创业的核心逻辑是缩短“Build-Measure-Learn”的周期。为了从实验中学习,就需要全面采集实验数据。交付基础设施通常会包含技术性的监控和数据采集(例如基于ELK的日志监控体系),提供性能、资源、系统告警等角度的数据。
单纯技术性的数据不足以对业务实验提供反馈,需要贯串用户体验,获取对业务有指导意义的数据。一个可供参考的框架是“海盗度量”:聚焦关注创新业务的获客、活跃、保留、推荐、创收(AARRR)这5个环节,从这个5个点上提出假设,然后用数据来证实或证伪假设。

金丝雀发布
金丝雀发布是一种控制软件发布风险的方式:在把新版本发布给全部用户之前,首先发布给一小部分用户,确保功能完好可用。金丝雀发布的主要目的是为了降低风险。新的软件可以先在与用户隔离的环境中接受UAT测试;如果新的软件有问题,受到影响的只是一小部分用户,不至于立即造成巨大的损失;如果新的软件有问题,可以立即回滚到旧版本。
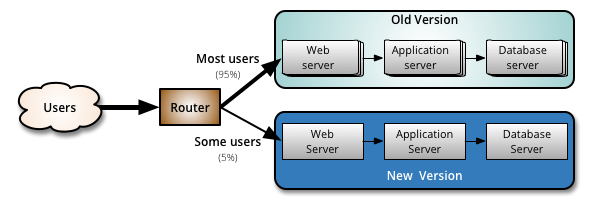
金丝雀发布最基本的形式,就是在前端反向代理上用路由技术把一定比例的用户导向“金丝雀”版本(例如Nginx可以支持多种筛选用户的方式)。在路由技术的背后,应该以凤凰服务器和不可变服务器来实现每个服务,服务的创建和回收应该是完全自动化的。同时还需要需要端到端的综合监控,根据有业务语义的目标(例如转化率)是否发生突变来判断金丝雀的效果。
Toggle架构
Feature Toggle的目标是,通过架构设计允许团队在不修改代码的前提下改变系统的行为。常见的一些需要Toggle的场合包括:避免多个交付版本的代码branching/forking;避免未完成功能的代码branching/forking;运行时动态改变系统行为,以实现一些特定能力,例如:线上受控实验、针对不同用户权限提供不同服务、回路熔断和服务降级等。
常见的Toggle可以分为4类:
- Release Toggle:某些功能已经存在,但暂时不向用户发布。主要目的是为了基于trunk开发、避免开发分支。静态,生存周期短。可以用Togglz之类工具。
- Ops Toggle:回路熔断,高负载或发生故障时自动降级服务。较动态,生存周期长。工具如Hystrix等。
- Experiment Toggles:用于支持线上实验(例如Canary Release、A/B Test等)。动态,生存周期较短。采用路由技术实现。
- Permission Toggles:用于给不同权限的用户提供不同的服务。引入统一的toggle router和toggle configuration,避免在代码中写条件。动态,生存周期长。
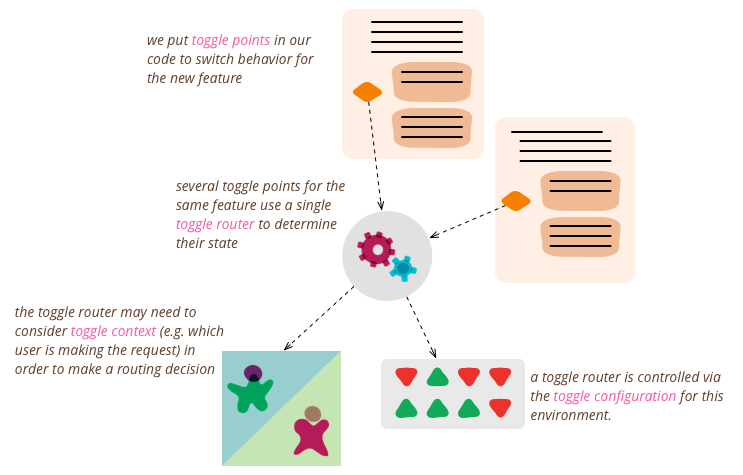
Feature Toggle也应该以服务API的形式暴露出来,并且鼓励用结构化的、人类可读的配置文件管理Toggle。
路由技术
通过路由切换的方式,让用户在不同的时间、不同的场合访问到不同的服务实例(可能是不同的版本)。路由技术可以用来支撑多种实验性部署技巧,包括蓝-绿部署(零宕机部署)、A/B测试、金丝雀发布等。这篇文章介绍了这些部署技巧直接的关系。
路由技术的实现与下层的弹性基础设施有很大关系,以AWS为例,有几种比较简单的实现蓝绿部署的方式:
- 对于单个EC2实例,可以修改它的Elastic IP
- 对于EC2集群,可以切换ELB背后的Auto Scaling Group
- 可以用Route53修改DNS重定向
- 可以用BeanStalk切换整个应用环境(如果应用部署在BeanStalk上)

Cloud Foundry也有一组实现蓝绿部署的最佳实践。
可视化和埋点
通过埋点获得系统运行时的信息,收集之后显示出来,从而把运维环境中的信息及时反馈回开发团队,缩短反馈周期。
常见的埋点方式有:
- 代码中埋点(例如New Relic、AppDynamics、Dynatrace)
- 监控进程(例如StatsD、collectd、fluentd)
- 日志(例如Splunk、ELK)
数据需要用一体化的、直观可视的仪表板展示出来,从而快速指导业务调整。Grafana和Kibana等工具提供了很好的仪表板功能,不过还是需要针对自己的情况加以定制。

小结
很大程度上,大部分组织的IT建设都谈不上“科学”。科学的基础建立在假说和实验之上,而在很多组织里,“有可能失败的项目”恐怕根本无法立项——更不用说“很有可能失败的项目”。降低做实验和犯错误的成本、从经验中尽可能多学习,是企业面对未知世界的唯一出路。然而快速的受控实验背后隐藏的是基础设施、软件架构、数据等多方面的技术支撑,把实验基础设施作为企业数字化旅程的阶段性目标,拉动各方面基础能力的建设,是建设数字平台的合理路径。
