我在之前的一篇文章中提到,机器学习项目如何管理,目前在行业内是一个普遍存在的难题。具体而言,对于这类项目,我们需要一套行之有效的工作办法,帮助一线工作者:(1)知道什么时候该做什么事;(2)知道什么时候该看什么指标;(3)知道什么时候可能有什么风险。这样一套工作办法的第一步,就是对一个机器学习项目设置合理的期望。
机器学习到底是在做什么
机器学习的基本过程可以用下面这张图来呈现:
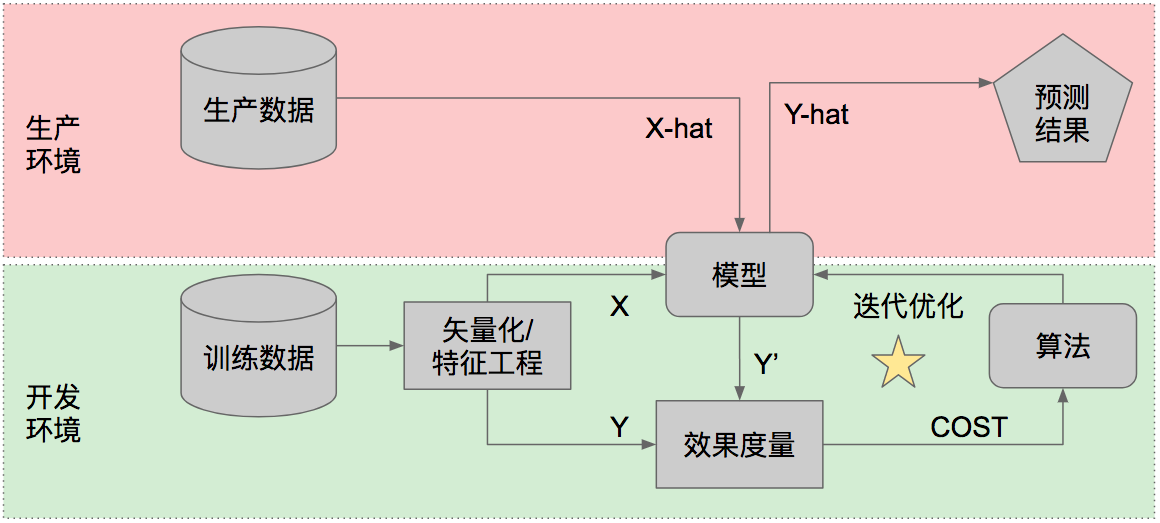
拿到已有的历史数据作为训练数据,我们需要对训练数据进行矢量化处理,把输入的不论什么形态的数据(例如文本、音频、图片、棋盘盘面)都转化成包含若干列的矢量。从矢量中我们再分出特征(X)和结果(Y),通常特征的列数远多于结果。
我们把X部分交给一个模型,算出与每一行训练数据对应的预测值Y’。所谓模型,就是一系列的权重系数,把这些权重系数用在一行输入数据上,就会得到针对这一行输入数据的结果预测。我们把Y’与Y对比,评判这一轮预测的效果。这个效果,我们用损失来度量。
然后我们用一个机器学习算法来尝试优化损失。所谓优化,就是不断尝试调整模型中的权重参数。调一次,再计算出一组新的Y’,再与Y比较效果。如此迭代,直到损失不再降低,或者达到预设的迭代次数。
所以,首先必须要记住:机器学习是一种优化任务。优化任务的目标不是找到“正确”的答案,而是找到一个“看起来不错”的答案。这一点会对我们看待这类项目的方式产生深远的影响。
如何为优化任务设置期望
传统意义上的软件开发(例如开发一个电商网站、开发一个社交app)是能够得到确定结果的:只要需求分析得够细致、原型设计得够保真、测试进行得够周全,你就可以准确地框定一个软件开发过程的产出结果,点击哪个按钮得到什么效果都是可以预先定义的。而机器学习项目则不然:不论分类、回归、聚类,本质上都是对某个损失函数迭代优化的过程。它没有唯一正确的答案,只是有希望得到看起来不错的答案。优化任务的逻辑不是因果,而是概率。
对于优化任务,我们不能问“是否正确”这个问题。有意义的问题是,模型的预测准确率能达到多少。一个缺乏经验的管理者可能会说“越高越好”,或者拍脑袋说出一个数字“90%”,显然这都不太有助于合理地管理期望和把控进展。暂时放下“准确率”的定义不谈,我们如何知道对于一个机器学习得出的模型应该期望什么样的准确率呢?显然大多数情况下预测准确率不可能达到100%,那么这个期望应该如何设置?
我们需要引入一个概念:贝叶斯错误率。简单说,贝叶斯错误率是对于一个问题有可能达到的最好的预测效果。贝叶斯错误率通常不是那么容易直接获得的,所以我们用人类的判断作为一个代理指标:一般来说,我们认为人类的判断错误率高于贝叶斯错误率,但是也相差不大。于是前面的问题变成了:对于一个机器学习得到的模型,我们期望它的预测准确率与人类的判断相比如何?
这个问题没有唯一正确的答案。有些时候我们希望模型的准确率高于、甚至远高于人类的判断;另一些时候,我们只需要模型的准确率勉强接近人类的判断,这样的模型就可以帮人类完成大量繁琐的工作量。对模型的期望设置不是一个技术问题,而是一个业务问题,在开始一个机器学习项目之前,就需要先与业务的负责人展开相关的对话。
如何定义“准确”
仍然以最简单的分类问题为例,模型的判别分为阳性(positive)和阴性(negative)两种,两种判别都有正确和错误的可能,于是总共就有了四种可能的情况:
- True Positive(TP):判别为阳性,实际也是阳性
- False Positive(FP):判别为阳性,实际却是阴性
- True Negative(TN):判别为阴性,实际也是阴性
- False Negative(FN):判别为阴性,实际却是阳性
一种朴素的“准确率”定义方法是“判别正确的比例”,即:

但是当样本的分布极其不均衡时,这个对准确率的定义会很有误导性。例如我们假设10000人里有150人患胃癌(阳性),经过对血样的分析,一个模型识别出100名患者(TP),有50名患者没有发现(FN),同时误报了另外没有患病的150人(FP);另一个模型则不做任何判断,直接宣称所有人都没有胃癌。我们直觉会认为前一个模型优于后一个,但朴素的准确率定义却给了我们相反的结论:
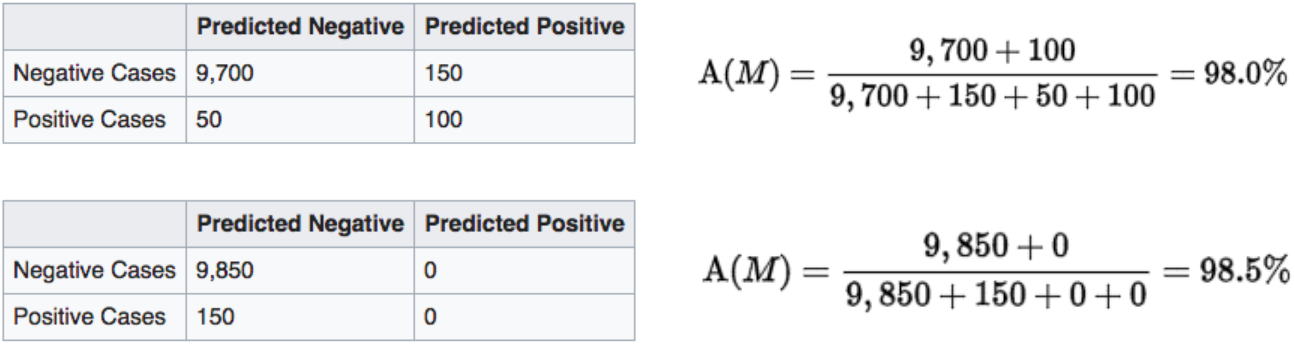
因为朴素的准确率定义有这样的问题,实践中更常用的指标是“精确率”(Precision)和“召回率”(Recall)。它们的定义分别是:
- Precision = TP/(TP+FP):在预测的阳性个例中,有多少是预测正确的?
- Recall = TP/(TP+FN):在所有的阳性个例中,总共找出了多少?
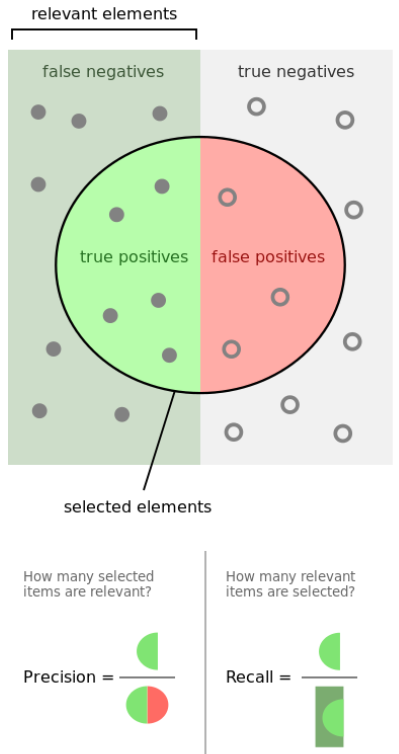
可以看出,Precision和Recall往往是互相矛盾的:如果追求找出更多阳性个例(提高Recall),那么阴性个例被误判为阳性的情况也会增加(降低Precision),反之亦然。在不同的业务场景下,需要追求的指标也会不同。例如在前面的体检场景下,我们会追求更高的Recall:尽量找出所有患病的人,有一些人被误报也没关系。而另一个极端场景是推荐顾客可能会卖的商品,这时我们会追求更高的Precision:推荐位只有5个,我们必须保证推荐的每一件商品都打中用户的兴趣点,至于还有几千个他可能感兴趣的商品没有被推荐,那并不重要。
以上我们看到的只是最简单的分类问题的场景。对于其他场景,可能需要引入其他度量准确率的指标。所以我们再次看到,采用什么指标来定义“准确”、应该如何权衡指标的取舍,这同样是一个与场景高度相关的业务问题。项目的管理者和业务代表需要清晰理解指标的含义、并合理设置对指标的期望。
然后呢……
如果项目的管理者和业务方代表能懂得机器学习是一类优化任务、能理解优化任务的度量方式、能针对这类任务设置合理的期望,在理解和把握项目进度与风险的路上他们就迈出了第一步。在下一篇文章里,我会拆解出机器学习类项目涉及的工作内容。读者将会看到,看起来高大上的机器学习、人工智能,实际上需要特殊技能和高中以上数学能力的只有极小一部分,其他都是普通的、确定性的软件开发工作,可以用典型的软件开发过程和管理方法来对待。针对份额极小、但有时非常重要的“自行训练模型”部分,我会给出更加细化的工作内容拆解,并提出任务拆分、进度管理、风险管理的相关办法。
