在前面的文章中我们看到,涉及机器学习、人工智能的项目,普遍地存在项目管理的困难。然后我介绍了针对这类项目如何设置合理的期望,并且深入分析了机器学习项目的工作内容。既然已经知道如何设置客户的期望、又知道可以做哪些事来逼近这个期望,那么围绕期望和动作进行任务的拆解、管理和可视化应该是顺理成章的。
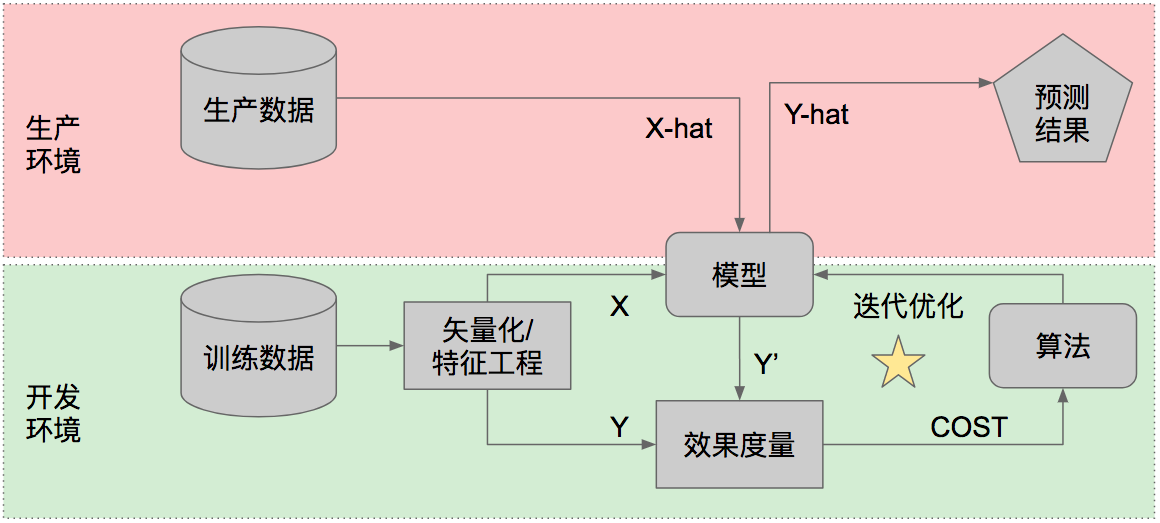
在前一篇文章中我们已经看到,一个机器学习项目涉及的三类九项工作内容当中,只有一项(“自行训练模型”,上图右下角标星星的部分)不是传统的软件开发任务。只有针对这项工作内容,我们需要新的任务拆解和管理方式,其他部分可以用标准的Scrum方法来处理。
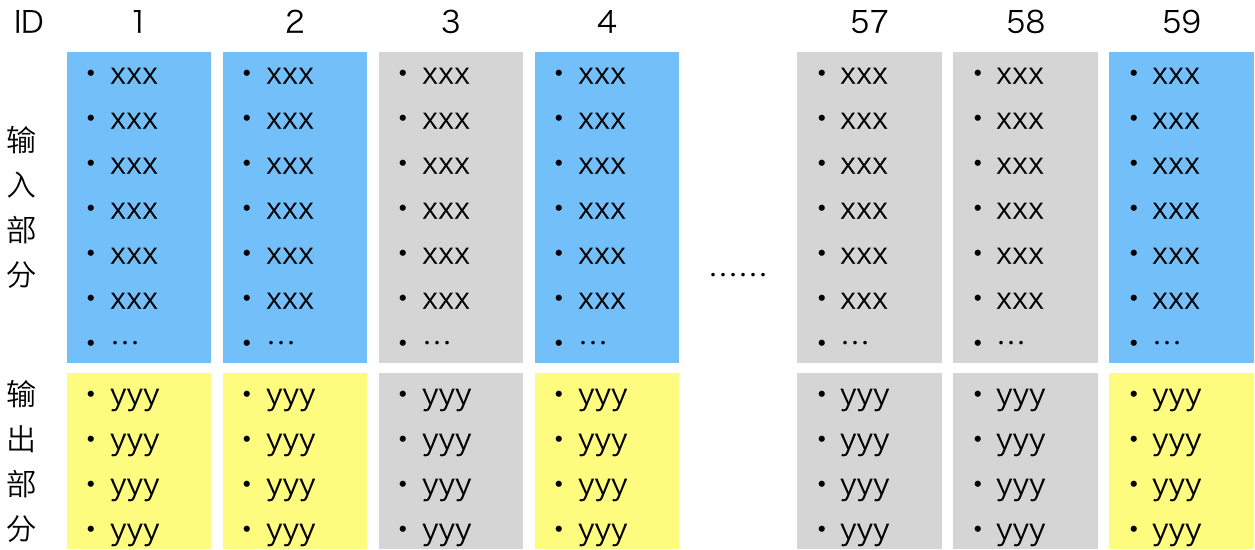
对于“自行训练模型”过程中的具体任务,可以沿用学校里做实验的概念,将每次模型训练记录为一次“实验”。每次实验应该包含两个部分:
- 输入部分,即实验的初始状态:数据从哪里来;如何对原始数据加工;选取哪些参数;如何训练模型
- 输出部分,即实验的效果:模型是否准确描述训练集;模型是否overfit训练集;有多少false positive;有多少false negative
于是我们得到了一张“实验卡”,上半部分记录实验输入,下半部分记录实验输出。

把若干张实验卡放在一个看板上,就得到了可视化的实验管理墙。在项目启动时,首先制定一部分实验计划(以一批实验卡的形式),记录每个实验设计的输入部分。每做完一个实验,就在对应的实验卡上记录实验输出。在项目进展过程中,也可以不断增加新的实验卡。项目过程中,做实验的优先级由上一篇文章中介绍的“自行训练模型的流程”来判断:从一个简单的模型开始,首先尝试能降低Bias的实验,当Bias逼近期望时,再做降低Variance的实验。
作为项目管理者,对着这样一面实验看板墙,需要关注的信息有以下几个方面:
- 看产出:实验效果(Bias-Variance组合)是否逼近预期?接下来应该做哪些实验?
- 看计划:实验计划是否完备?是否考虑到各种可能的算法?是否考虑到各种数据来源?是否考虑到各种数据加工方式?
- 看进度:做实验的速度有多快?训练集获取是否耗时太长?模型训练是否耗时太长?是否需要优化训练算法?是否需要增加计算资源?是否需要提高数据流水线自动化水平?
用这种方法,我们可以把看似神秘的机器学习项目拆解成独立、可讨论、有价值、可估计工作量、相对较小、可测试(INVEST)的实验卡,于是我们可以用Scrum方法来管理和度量围绕这些卡开展的工作。
