这篇文章主要目的是面向初接触大数据的朋友简单介绍大数据平台基础建设所需要的各个模块以及缘由。
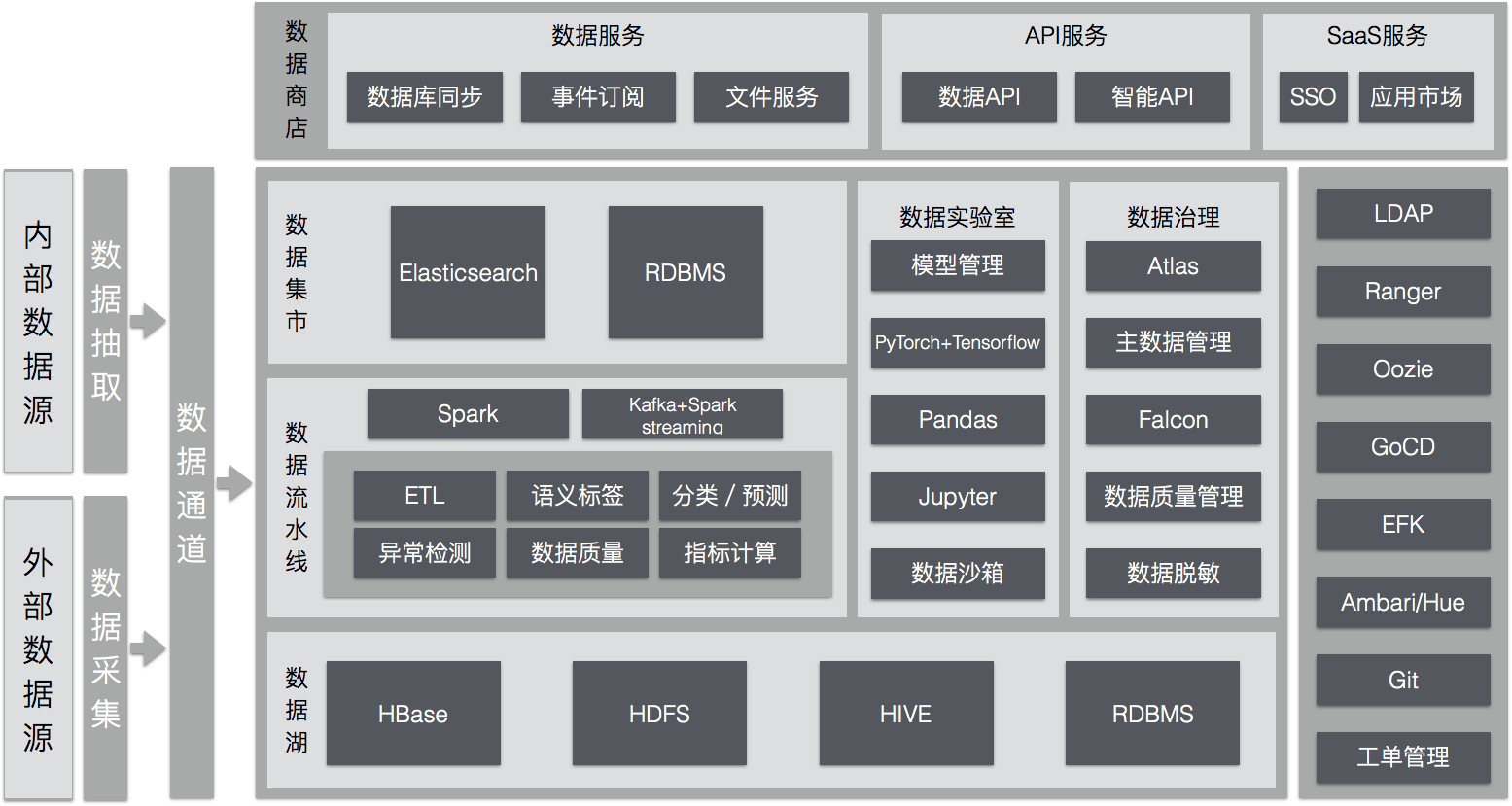
数据仓库和数据平台架构
按照Ralph Hughes的观点,企业数据仓库参考架构由下列几层构成:
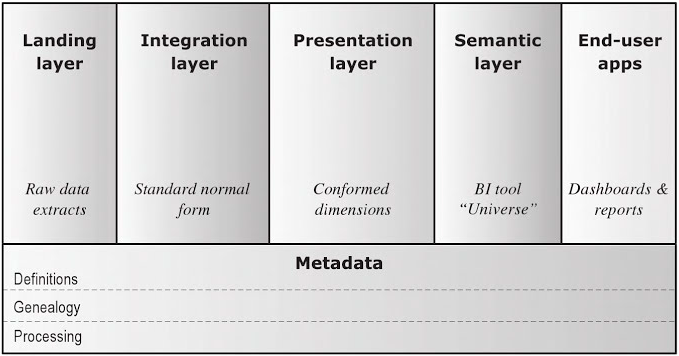
- 接入层(Landing):以和源系统相同的结构暂存原始数据。有时被称为“贴源层”或ODS。
- 整合层(Integration):持久存储整合后的企业数据,针对企业信息实体和业务事件建模,代表组织的“唯一真相来源”。有时被称为“数据仓库”。
- 表现层(Presentation):为满足最终用户的需求提供可消费的数据,针对商业智能和查询性能建模。有时被称为“数据集市”。
- 语义层(Semantic):提供数据的呈现形式和访问控制。例如某种报表工具。
- 终端用户应用(End-user applications):使用语义层的工具,将表现层数据最终呈现给用户,包括仪表板、报表、图表等多种形式。
- 元数据(Metadata):记录各层数据项的定义(Definitions)、血缘(Genealogy)、处理过程(Processing)。
把数据放到一起:数据湖
企业大数据平台的核心是把企业数据资产汇集一处的数据湖。ThoughtWorks的“数字平台战略”这样描述数据湖:
数据湖……的概念是:不对数据做提前的“优化”处理,而是直接把生数据存储在容易获得的、便宜的存储环境中;等有了具体的问题要回答时,再去组织和筛选数据,从中找出答案。按照ThoughtWorks技术雷达的定义,数据湖中的数据应该是不可修改(immutable)的。
来自不同数据源的“生”数据(接入层),和经过中间处理之后得到的整合层、表现层的数据模型,都会存储在数据湖里备用。
数据湖的实现通常建立在Hadoop生态上,可能直接存储在HDFS上,也可能存储在HBase或Hive上,也有用关系型数据库作为数据湖存储的可能存在。

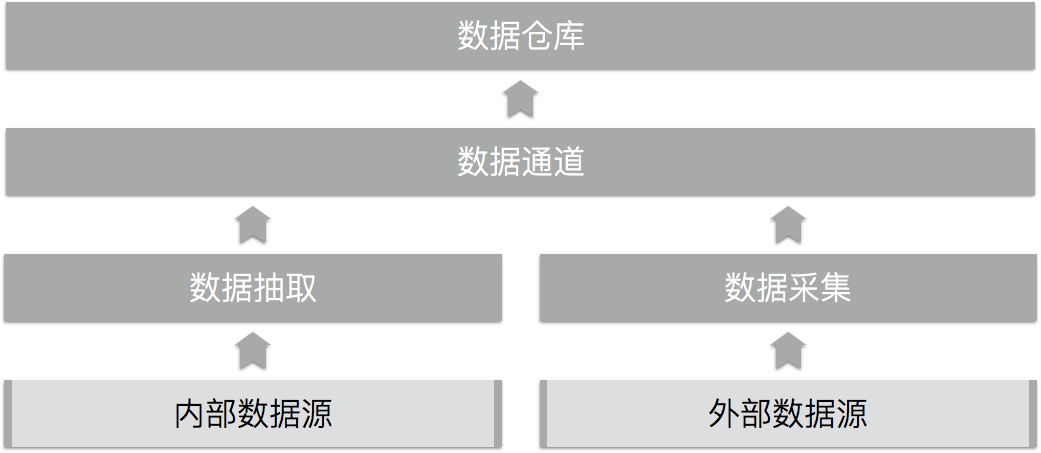
接入原始数据:数据通道
企业大数据平台创造价值的基础是能把各种与业务有关的数据都接入到数据湖中,这就需要针对各种不同的数据源开发数据通道。数据接入的连接器(connector)通常是一个定时执行的任务,技术选型随数据源而定,有些项目采用定制开发的数据接入任务,也有些项目采用像Talend这样的套装工具。对于来自企业之外乃至互联网上的数据,可能需要编写爬虫。
数据加工处理:数据流水线
在数据湖内部,数据会经过“接入层 => 整合层 => 表现层”的加工处理链,逐步变成用户可用的形式。其中每一层的加工处理,至少包含ETL(提取-转换-装载)、指标计算、异常检测、数据质量管理等工作,还可能对数据进行语义标签、分类预测等更深入的操作。
数据流水线的技术选型主要分为流式数据和批量数据两大类。在Hadoop生态中,Spark常被用于批量数据处理,Kafka和Spark Streaming的组合常被用于流式数据处理。

面向业务领域:数据集市
整合层存放了整个企业的数据,并且以规范化的、巨细靡遗的形式(例如Data Vault)对数据建模。表现层则与之不同:数据集市中的数据是针对业务应用领域选择出来的,并且建模形式更方便查询(例如宽表)。数据集市的技术选型也是为了查询的便利,例如采用ElasticSearch或关系型数据库,因为这些工具都支持很完备的查询功能,而且用户也非常熟悉。

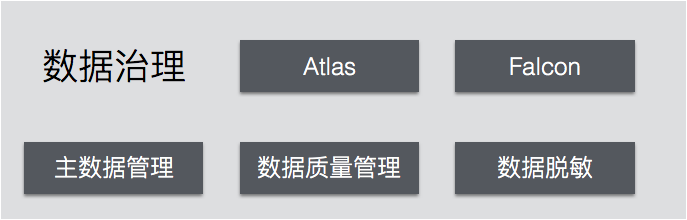
保障数据质量:数据治理
在实施数据湖的时候,有一种常见的反模式:企业有了一个名义上的数据湖(例如一个非常大的HDFS),但是数据只进不出,成了“数据泥沼”(或数据墓地)。造成这种现象的原因之一,就是因为缺乏必要的数据治理:数据缺乏一致性、数据质量不佳,导致用户无法从数据中获得可靠的洞察。
数据治理的基本工作包括了数据脱敏、数据质量管理、主数据管理等。Atlas、Falcon等工具提供了数据治理的技术能力。
探索未知:数据实验室
数据自服务能力的一大亮点是鼓励小型的、全功能的团队自行从数据中获得洞察。为了形成从数据到洞察的快速响应循环,业务团队需要对整合层甚至接入层的数据做快速的探索和实验,而不是先完成接入-整合-表现的整个数据处理链。数据实验室提供模型管理和数据沙箱的能力,让业务团队能用Python、Java等通用编程语言快速展开数据探索和实验。PyTorch、Jupyter、Pandas等工具提供了便捷的途径来搭建数据实验室。

供给应用:数据商店
确定要提供给业务团队使用的数据,就可以进入数据商店,包装成数据产品或服务的形式供应出来。基础的形态可以是直接对外提供数据(通过数据库同步、事件订阅、文件服务等形式),在微服务语境下我们更鼓励的方式是以API的形式对外暴露数据服务,更进一步的想法可能是以SaaS服务的形式对外提供。例如Forbes认为以下几种数据服务已经具有较高的成熟度和接受度:
- 用于benchmark的数据
- 用于推荐系统的数据
- 用于预测的数据

大数据平台的全貌
到这里我们已经看到了大数据平台各个组件的来由和形状:以数据湖为中心,由数据通道接入原始数据,经过数据流水线的加工处理,根据业务需求进入不同的数据集市,业务用户或是通过数据实验室探索、或是从数据商店获得自己需要的服务,整个过程接受数据质量和一致性的治理。再加上系统监控、日志管理、身份认证、任务调度、配置管理、项目管理、持续交付等通用的能力,我们就看到了一个企业级大数据平台的全貌。