-
Cybersyn的系统架构
前文《半个世纪前的大数据时代》讲到,1970年代初,英国的控制论学者斯塔福·比尔应阿连德总统之邀,远赴智利去开发一套用于管理国有经济的大数据IT系统。本文将介绍这套远远超前于时代的系统是如何在当时的技术条件下架构和建设起来的。

生产大战中的控制论
在阿连德执政的第⼀年,智利政府开始将国内最重要的⼀些⼯业收归国有。到1971年底,政府已经把所有主要矿业公司和68家最重要的⼯⼚由私有转为公有。智利正在打⼀场“⽣产⼤战”,提⾼⼯业⽣产⽔平被视为智利社会主义成功的关键。管理已经成为国有化进程的⼀个核⼼问题,政府计划把⼯业管理作为第⼆年的⼯作重⼼。国有经济的⾼速发展创造了⼀个笨重的、智利政府从未⻅过的怪兽,这是问题的根本所在。
在这样的大背景下,斯塔福·⽐尔于1971年11⽉4⽇星期⼆抵达智利,邀请他的是智利国家开发公司(CORFO)的技术主管费尔南多·弗洛雷斯。经过弗洛雷斯的介绍,比尔对智利面临的挑战有了一个大体的理解。控制论思考帮他识别出如何改进智利政府管理经济的⽅式。例如,⽐尔发现政府可以建⽴新的通信渠道,促进数据交换,提升政府决策速度。同时他也认识到⾃⼰⾯临的约束。成⽴新的政府部⻔或是对现有政府机关进⾏根本性重组可能可以极⼤提升管理能⼒,但当前的关键是要快速⻅效,政府没有时间来成⽴新的调控部⻔,也⽆法⼤规模修正和重建现有的机构。
在⽐尔和弗洛雷斯的构想中,控制论科学扮演着双重⾓⾊。控制论的管理视⾓,尤其是可⽣存系统模型,能够指导CORFO所需的组织变⾰、避免实施⻓远来看低效甚⾄有害的权宜之计。同时,控制论中关于反馈与掌控的思想能够指导开发⼀套新的科技系统来改善国有经济的管理,从⻋间直到CORFO办公室。发源于⽐尔的“⾃由机器”思想,这样⼀个系统将会搭建起实时信息交换的网络,其中会⽤到⼤型主机技术。管理者和政府官员将能够基于实时数据来做决策,并能够快速调整⾏动⽽不被政府官僚体系束缚。管理控制论还能改善政府从国营企业获取信息的⽅式。当这些数据流得到改善,弗洛雷斯和⽐尔相信政府能加强对智利⼯业的管控,并最终赢得⽣产⼤战。
基于这一构想,比尔提议建设Cyberstride项目,后来这个项目改名为“Cybersyn”。Cybersyn系统结合了比尔早期著作中的思想,包括他的文章《自由机器》中提到过的控制室。这个系统将依赖于每天从国有产业采集来的数据,用大型主机对未来经济行为进行统计学预测。随着智利的计算机操作员输入更多来自企业的最新数据,系统每天都会对预测做出更新。
只有一台计算机的网络
Cybersyn的骨干是一个支持实时数据交换的通信网络。将国家开发公司(CORFO)与工厂车间连接起来,就能建立“向上滚动”式管理所需的条件,使政府能够快速处理诸如原材料短缺等紧急状况,并及时调整政策。最新的生产数据还让经验丰富的管理者(通常位于行业委员会或更高的级别)能帮助缺乏经验的干预者识别他们工厂里的问题,并在必要时调整生产行为以达到国家的目标。按照比尔的构想,这种信息交换会以很快的速度持续发生,并且总是以指导行动为目标。通信、适应和行动,这些都是管理控制论的核心要素,它们就是比尔在组织与生物有机体之间发现的共性:两者都需要快速适应,才能在变动的环境中生存。弗洛雷斯与比尔一样重视时间,两人都认为:数据如果不能指导行动,那就是被浪费了。
除了通信网络和用于生成经济预测的软件,Cybersyn项目还需要一个计算机程序来模拟智利经济。另外,CORFO成员会把生产数据汇总,并以直观的形式显示在指挥室里,以便政府的决策者理解。这些数据显示会帮助决策者看清国家经济形势,并基于智利工业的现状制定政策。
按照比尔的提议,Cybersyn项目的设计考虑到了智利科技的局限。国家计算机公司(ECOM)的主管雷蒙多·贝卡只给比尔提供了一台大型主机的处理时间,这是一台IBM 360/50,ECOM当时性能最强的主机。鉴于计算机公司只有4台主机,全都非常繁忙,贝卡只能提供一台机器是完全能理解的。但这就意味着比尔的团队必须用一台计算机来建设一个计算机网络。
对这个看似不可能的要求,比尔给出了设计方案:他为Cybersyn项目设计了一个通信网络,整个网络都连接到这一台大型主机。为了实现这个非传统的网络架构,比尔和团队需要找到一种便宜的方式来实时、长距离传输数字数据和文本。他们找到的办法是电传机(电传打字机),这些机器已经通过现有的电话线、卫星或微波通道联网。在1970年代初,电传机已经在全世界广泛使用,不是什么高新科技。每台电传机都有一个身份识别号,就跟电话号码类似,用户拨打这个号码,就可以在两台机器间建立连接。然后用户可以用电传机的键盘输入信息;信息会被翻译成纸带上的打孔,再通过网络把打孔纸带的信息传输出去;另一端的电传机则读取纸带,翻译出原来的信息,从而完成信息的传播。用户往往会预先准备好纸带,以便尽量减少连接网络的成本,不过电传机也允许两端的用户通过打字来回交谈。一旦收到信息,接收方的电传机就会在一串嘈杂的咔嗒声中打出一行行文字,听起来不像是传真机,倒更像是电子打字机。在1970年代初的智利,电话尚属稀缺资源,电话网络也不够可靠。电传机提供了另一种国内乃至国际通信的方式。所以,比尔提议在电传机网络的基础上建设Cybersyn项目,于是整个通信网络就只需要一台IBM大型主机。
比尔提议的系统工作方式如下:干预者用电传机从各自的企业将生产数据发送给国家计算机公司的电传机,计算机专家们再把数据以打孔卡片的形式输入到主机系统中;计算机会运行统计软件,将新的数据与过往采集的数据对比,寻找显著的差异;如果发现重大差异,系统会向计算机操作员告警,后者则通过电传网络把数据发送给CORFO和相关的干预者,随后CORFO会联络这些干预者,以便更好地了解现状并帮助解决问题。
统计软件
在部署电传网络的同时,比尔向安达信请求帮助,希望他们参与到后台软件的开发中。安达信的评估结果是,他们可以在1972年3月中旬之前编写并安装一个“临时套件”。这个临时的软件只能接受限定范围内的输入值,但至少能在原定的期限之前给智利人一套软件先用起来。为了在3月的交付期限前完成这个临时套件,他们需要砍掉很多边角。同时安达信会负责设计功能完备、长期使用的软件套件,但长期套件的开发和实施由智利团队负责。在此过程中,三名安达信咨询师会出差到圣地亚哥提供支持:一人负责安装临时套件,一人帮助智利程序员编写长期套件,另一名高级合伙人会为团队提供指导、并在项目结束时签字代表咨询公司正式签字。
Cybersyn的软件系统是控制论管理领域的新突破。它是比尔的可生存系统模型的第一个软件实现。这个程序还实现了一个新的、从未实验过的贝叶斯统计预测方法,这个名为哈里森-史蒂文斯方法的统计预测方法1971年12月才首次发表在《运筹学季刊》上。安达信的咨询师阿兰·邓斯缪尔在为项目做文献综述时偶然发现了这个新方法。他说服比尔这个方法可以识别生产数据中的显著变量,并根据初始数据点预测未来的趋势:是线性趋势、指数趋势、还是步进函数、或者只是暂时的异常数据。用这个方法,软件就不止能记录和汇总历史数据,还能对未来作出预测。而且一旦计算机操作员输入新的生产数据,软件就能自动调整其预测。
哈里森-史蒂文斯方法的提出者之一杰夫·哈里森是华威大学统计学系的创始人和首任系主任。在大学给他的讣告中说“他远远超前于他的时代”,这话绝非溢美之词。如果你看Wikipedia的“统计学历史”词条,其中有这样一段话:“1965年……林德利把贝叶斯方法介绍给更广泛的听众;1980年代,贝叶斯方法的应用大幅增加。”似乎贝叶斯方法在1970年代没有取得重要的进展。然而哈里森于1971年发表的文章《一种用于短期预测的贝叶斯方法》可能是首次将贝叶斯函数用于统计预测,Cybersyn则可能是第一个实现贝叶斯预测方法的计算机程序。然而在他的年代,因为计算能力的局限,贝叶斯方法不被学界主流认可;等到1980年代计算能力提升、尤其是马尔科夫链蒙特卡洛方法的发现解决了大量计算问题使得贝叶斯方法受到重视,哈里森就直接被历史跳过了。考虑到现在贝叶斯预测方法在机器学习领域的热门程度,哈里森近乎默默无闻的一生不禁令人唏嘘。
【杰夫·哈里森可能仅有的一次出现在学术领域之外的出版物上是在一本叫做《难以置信的巧合》的伪科学著作上。这本书收录了很多奇妙的偶然事件,其中一个故事讲到哈里森在给某一届学生上第一堂概率课的时候抛了一个硬币,本打算借此讲解概率的基本概念例如硬币正反面落地的概率各为1/2,没想到硬币落下以后不偏不倚地立在了桌上。】
经济模拟器
统计软件运行的结果会进入一个经济模拟器,用于模拟智利经济状况并预测未来走势。比尔希望经济模拟器成为“政府的实验室”。一旦完成,这个模拟器能帮助政府决策者跳出日常事务进行全局决策,并实验多种不同的长期经济政策。所以这个模拟器需要反映不断变化的经济行为,尤其考虑到智利经济正处于转型期,这一点就愈发困难:它不仅要接受不断变化的输入值,还要不断调整变量之间的关系,并引入新的考虑因素。在真实世界中,这些变化不断在发生,因此模拟器的模型也需要能处理动态的变化。
比尔决定采用一种不太常见的建模方式。当时大多数经济模拟都采用“输入-输出”方法,用庞大的数据集来计算不同生产过程之间的相关性。这种分析方法可能需要几年时间来采集数据,然后用固定的方程式计算系统行为。比尔批评这种方法“死板得无可救药”。如果“目标是重组经济”,比尔写道,那么这种刻板的方法就是“糟糕的工具”。为了寻找不同的方法,比尔把眼光投向了著名的MIT工程师杰·福瑞斯特的研究。
在计算史上,福瑞斯特最广为人知的成就是发明了磁芯存储器,以及领导了“贤者”陆基防空系统的计算机设计团队。从1950年代后期开始,福瑞斯特的研究重心已经转移到工业管理领域。他对建模随时间变化的复杂系统尤为感兴趣,并把这个这个领域称作“系统动力学”。福瑞斯特鼓励政策制定者借助模型来识别出为数不多的一些关键参数,通过调节这些参数就能获得期望的结果。随后政策制定者就可以集中精力在这些领域。为了编程实现他的动态系统模型,福瑞斯特发明了DYNAMO编程语言,比尔发现这种语言很适合用来编写新的经济模拟器。
比尔找到了罗恩·安德顿,一位系统工程师、运筹学家、以及英国首屈一指的DYNAMO专家,请他投入到经济模拟项目中。到1972年3月,安德顿已经实现了经济模拟器的最初版本,这个软件被命名为CHECO(“智利经济模拟器”的英文缩写)。最终,安德顿写道,这个模拟器将使CORFO“对包含10到100个变量的系统逐步获得动态的理解,作为对比,缺乏系统指导的大脑只能理解5到10个变量。”同时,邓斯缪尔带着完成的临时软件套件从伦敦来到了圣地亚哥。3月中旬,第一批结果数据从工厂车间传到了CORFO。Cybersyn系统的流程走通了。
-
印度儿童诗雅拉尔之死
来自里格瓦尔村、6岁大的诗雅拉尔·雅达夫已经发烧和头疼三天了。当他的皮肤开始浮现病态的黄色,他的父母找了一个巫医来进行“jhar-phook”(把魔鬼的灵魂赶出孩童的身体)。然后他们又带着孩子去看了一个村里的无证医生,他给孩子打了一针,退烧效果维持了一天。第二天,诗雅拉尔的父亲阿南德从农田里回家,发现孩子发着高烧、呼吸困难。恐慌的父亲想带孩子去拉坦浦尔镇的基层卫生中心去,但拉坦浦尔镇远在25公里外,当天最后一班去镇上的大巴早已发车。村长热心地给他们找了摩托车。基层卫生中心的值班医生做了简单的检查,叫阿南德赶快带孩子去比拉斯浦尔县上的医院——又是30公里路程。阿南德身上只有200卢比(约合20元人民币),于是他恳请医生照顾孩子一夜,他自己回去筹钱,但医生拒绝了他。阿南德只好带着诗雅拉尔赶最后一趟大巴回到村里,此时孩子的意识已经模糊。孤注一掷的阿南德用家里的一亩地和地里的所有庄稼做抵押,借到了8000卢比(约合800元人民币)。一家人紧握着钞票,与轻声喘息的男孩一起等待太阳升起。凌晨4点,诗雅拉尔说想喝水。当母亲端来水,孩子已经离世了。

在包括中国在内的很多国家,疟疾几乎已经绝迹。但在印度中部的恰蒂斯加尔邦,它仍在投下死亡的阴影。2010年10月到12月之间,恰蒂斯加尔邦爆发了恶性疟疾流行。据邦政府的统计,两个月中全邦共有32人因疟疾死亡。然而,仅比拉斯浦尔县的加尼亚黎村一地就有7例死亡病例。“人民健康扶助团”(Jan Swasthya Sahyog,简称“JSS”)在这个村里设有医院。在附近的科塔乡,JSS的社区医疗团队进行了250例口述验尸,其中200人被证实死于疟疾。如果一个县一个乡就有这么多人死亡,整个邦的数字恐怕只有天知道。
根据政府的官方数字,印度全国每年有200万人患上疟疾,约700人因此丧生。然而据世界卫生组织的估计,印度每年有1500万病例,其中2万人死亡。由加拿大一家机构发起的“百万死亡研究”的估计是每年有15万到22.5万人死于疟疾——印度传染病控制部门则对这个研究项目表达了强烈的抗议。大多数疟疾死亡发生在家里,因此不会被计入正式的统计数据。正式的数据来源仅限于公立卫生机构,并且要求疟原虫阳性涂片作为证据,然而大部分病人根本没有进行这项化验。
在缺乏正确信息的情况下,公共卫生政策必然是错误和低效的。而且越是偏远贫困的人群,遭受的损害就越是严重。政府的官方数据显示,50%的恶性疟疾病例和90%的死亡病例发生在被称为“阿迪瓦西”的部落民当中,而他们仅占全国人口的8%。缺乏公共卫生基础设施使得偏远贫困地区大部分病痛与死亡无人知晓,而统计数据的缺失又使得政府疏于投资基础设施建设。这成了一个难解的死结。
* * *
黄昏的阳光穿过柚木和娑罗的树叶,在车窗前洒下斑驳的光影。越野车二档通过安查纳克玛老虎保护区泥泞的道路。JSS的医院位于恰蒂斯加尔邦西北部的加尼亚黎村,离比拉斯浦尔县城23公里。进村的道路需要穿过玛尼亚黎河,当季风带来大量雨水,这条道路就会被河流阻断。在降雨稀少的旱季,越野车能够平稳地驶过河水,在日落前进入村庄。
村边的几栋水泥房屋本来是为一个灌溉项目而建的。这个政府投资的灌溉项目无疾而终,于是JSS把这几栋房屋改造成了转诊医院,包括门诊部、70张床位的住院病房、一个功能齐全的化验室和两个手术室。现在这家医院每天接诊400名病人,并在三个偏远地区设立分中心,向居住在森林边缘的人群提供基本医疗服务。
现代科技与这里的环境显得有些格格不入。基础设施的薄弱当然是原因之一:这里没有3G信号,2G信号时断时续,停电也是家常便饭;另一方面,村里人识字的不多,医院的医生、护士和工作人员也几乎从未接触过智能手机。病人拿到的药品用塑料袋装好,药盒上贴着一张纸,上面画着代表服药时间的太阳/月亮图标和代表剂量的药片图标。一个房间里纸质病历堆积如山,接诊时护士就要去这个房间里翻找病人的病历交给医生。这是JSS医院的日常。
Bahmni(读作“巴姆尼”)的目标是让JSS医院、以及其它成千上万类似的医院实现信息化。ThoughtWorks印度公司从2013年开始的这个产品,其核心是一个开源的电子病历(Electronic Medical Record)系统OpenMRS。这个软件内建了一套标准的医疗信息记录数据体系,在北美和南美的一些医院里的实施收到了很好的反馈,并且有一个活跃的社区(包括医学专家、公共卫生专家和IT专家)在不断完善它。但OpenMRS缺省的用户体验不是为JSS这样的医院设计的:它假设了IT水平较高的用户,界面是针对电脑屏幕设计,而且使用过程中需要一直连接网络。于是ThoughtWorks的团队与JSS的医生们协作,在OpenMRS的基础上开发了适合低资源环境的前端用户体验:在平板电脑上使用,界面操作简洁易懂,断网情况下照常工作,等连上网再同步数据。这就是Bahmni的雏形。
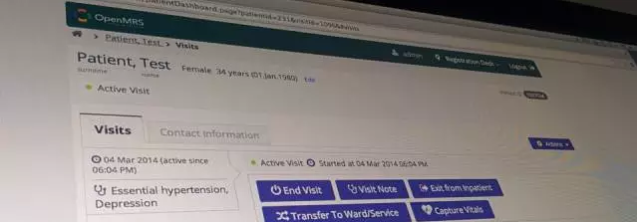
随后,为了让医院信息化端到端拉通,Bahmni产品又整合了几个其它的开源软件。Odoo(曾经叫OpenERP)提供了药房库存管理、账目管理、财务会计的功能;dcm4chee实现了放射影像的信息化集成;OpenELIS打通了化验流程。今天的Bahmni已经是一个完整的一站式医院信息化系统,覆盖挂号、门诊、化验、影像、住院、诊断、手术、处方、取药、预后跟踪的整个医疗服务流程。有了及时准确的信息在手边,医生的诊疗能够更加精准、更加高效。
一家区级转诊医院的信息化能够积累一个区、几个乡、几十个村的电子病历。如果一个邦的几十个区都有这样一家医院,把它们的电子病历信息汇总起来,政府卫生部门就能得到完整真实的公共卫生数据。如果全国的几十个邦能做到医疗信息联网,国家的公共卫生政策和基础设施投资就能有的放矢。在雅鲁藏布江下游和喜马拉雅山南麓,孟加拉和尼泊尔的政府都有着这样的愿景。他们与ThoughtWorks的咨询师一起,规划为期数年的IT项目,目标是建设全国联网的医疗信息交换(Health Information Exchange,简称“HIE”)体系。
HIE是一个世界级的难题。医疗信息的联网需要打破卫生、财政、人力资源、社会保障等多个领域的壁垒,需要解决可用性、可靠性、可维护性、信息安全等技术挑战。美国政府每年投入到HIE的投资平均到每个临床医生身上达1.7万美元,至今也未能实现全国联网的目标。孟加拉和尼泊尔这两个位列世界银行中低收入列表的国家希望达成这个梦想,Bahmni是他们选择的武器之一。这个开源、易于配置、易于管理的软件系统,使两国国内的软件团队也能掌握实施和维护能力,从而极大地降低了实施成本,而且——更重要的是——最大程度地避免了对外国高科技企业的依赖。Bahmni采用国际通行的医疗信息交换开放协议HL7 FHIR(读作“fire”),所有主流电子病历系统都能与之集成交换信息。ThoughtWorks的团队与世界各国的HIE实践者紧密协作,将Bahmni融入了OpenHIE信息架构,使国家的HIE建设成为了一个开放的产业生态,政府、企业、研究机构、非营利组织、国际发展机构都能参与和贡献。
* * *
诗雅拉尔死后3天,他的小表弟,1岁大的提拉克兰也出现了同样的症状。提拉克兰的父母已经提前找人借了钱,他们立即租了一辆轿车把孩子从卡吉路的社区卫生中心送去比拉斯浦尔。但社区卫生中心没有空闲的氧气瓶给这个呼吸困难的婴儿。提拉克兰没有挺过去比拉斯浦尔的这段路程,给他的父母留下了1万卢比(约合1000元人民币)债务,和无尽的悲伤。

JSS医院的医生们和Bahmni的开发者们希望,在不远的将来,政府卫生部门能从及时准确的公共卫生数据中窥见恶性疟疾爆发的前兆,及早把青蒿素等药品和预防、诊断、治疗疟疾的知识送到每个村庄,让诗雅拉尔和提拉克兰这样的孩子不再因为疟疾而夭折。
我们在为这个梦想奋斗。
-
2016年,读过的那些好故事
2016年是忙碌的一年。为了MBA毕业论文,大半年里所有的业余时间都被耗尽。好在总算功不唐捐,战胜了各种拖延症,写出一篇还算对得起自己的论文,同一个主题在QCon做了一次演讲。而且托东野大神的福,竟然还读了64本书,其中颇有不少打得出5星的好故事。

中国的故事
- 大唐李白(少年游、凤凰台、将进酒) - 既有精彩的故事,又有旖丽的文字,典故又多,读起来觉得身轻如燕。我唐啊,真是繁华瑰丽,美不胜收!
- 叫魂 - 重要的不在于那个事本身是什么,而在于当时的人是怎么看那个事,并从这个“怎么看”折射出当时的制度环境。方法真好!
- 天国之秋 - “这个故事说明了我们认为跨越文化与距离的联结有时其实我们虚构的东西。当我们庆幸终于看透将我们与另一个文明隔开的那扇阴暗的窗户,心喜于在另一边的阴影之间发现隐藏其中的类似形体时,有时我们不晓得自己只是在凝视我们自己的倒影。”
- 乱世潜流 - 罗大师一贯的风格,从时人眼光看当时事。讲辛亥到北洋一段时人的思想变迁,与《大波》放一起看,正是相映成趣。
外国的故事
- 巨人的陨落 - 好像以前没有这种全球视野的演义小说吧?细节很靠谱。要是笔锋再好一点就能写成一战背景的冰与火之歌了。
- 古拉格群岛 - 本来只想给四星,但是当看到作者说“并不是什么人都宽恕,我只宽恕倒下的人”,就决定给他五星了。真实的信息有最大的力量。
- 周期表 - 漂亮的小故事,没有特别着意写奥斯维辛,可是那种深远的影响随处可见。
- 新自由主义简史 - 知道它的历史,才知道所谓“市场主导”、“自由至上”等观念是多么新鲜、多么人为。
- 生命如歌 - 震撼人心。强烈推荐所有对国际发展和全球医疗感兴趣的人看。
- 底特律 - 我们太习惯于经济的高速增长,以至于我们忘记了盛衰有时。一座曾经拥有上千万人口的城市如何衰落成不到70万人口,这是当代人几乎无法想象的幻景。
- 资本的终结 - 简洁的理论,清晰的数据,有力地阐释今天世界的种种现状。要多么努力地自我欺骗才能死守住自由主义经济学观点而不信这么明显的道理?正如齐泽克所说,freedom hurts。
虚构的故事
- 没有女人的男人们 - 虽说都是小故事,可是写得很真挚,而且致敬变形记那篇相当妙。
- 银河帝国(8~12卷) - 什么机器人三定律,其实只是写好玩的本格推理可以用到的一组预设条件而已。幻想的前提条件用好了以后,写出来的本格推理小说果然严密又精彩,连悬疑感都写出来了。但是仍然不怎么喜欢“人类整体”这个概念…而且心理史学必须建立在心灵控制的基础上,这样合适吗?
- 解忧杂货店 - 很感人的小故事,而且结构很周密
- 恶意 - 写作手法真漂亮,不但推理层层推进,叙述的视角也不断切换,佳作。
- 歪笑小说 - 不剧透,不过最后一页的大反转可真是令人感动啊,满满的都是温情啊。
科技的故事
- 凤凰项目 - 很棒的故事。可惜的是,最后那段介绍的持续交付,需要相当高的技术能力。所以,雇不起优秀的技术人才、玩不转docker的企业,就只能眼睁睁看着比自己强且敏捷的对手屠杀自己,毫无反抗可能性。
- 精益企业 - 套路非常清晰,材料非常齐全,Jez桑的集大成之作,IT驱动组织转型的必读
- Cybernetic Revolutionaries - 尝试用政治与技术的合力建设一个更公正的社会,这样的努力会打开很多新的可能性:技术的、知识的、政治的、等等。Cybersyn是重要的技术和历史遗产,即使它的宏大愿景从未实现。
- 控制论 - “预测一个消息的未来,就是用某种算符去运算这个消息的过去……最优预测问题的解决仅仅取决于要加以预测的时间序列的统计性质”——写于1948年,跪了。
-
科技想要的 vs. 人民想要的
2016年12月14日晚,我就《半个世纪前的大数据时代》一文与读者进行了一场主题交流。以下是对交流现场的记录。

问:你如何看待控制论和信息论的关系,以及控制论对互联网公司决策的影响?
答:值得注意的,控制论在最近十来年已经不怎么被提及了。不是因为它过时。恰恰相反,是因为它渗入了各个学科、尤其是科技和商业领域的各个方面。控制论与“前控制论”管理思路的关键区别就一个词:反馈。“瀑布式”的管理理念认为,我只要提前做好设计,一步一步走下去,最后就能达成目标。然而控制论——用人体震颤这一例子——精辟地指出:别说管理什么大项目了,如果只有预先设计没有反馈和调整,你连杯水都拿不起来。
迟至2000年前后,IT行业对反馈还不是那么重视的,大家看重的仍然是计划和执行。证据是2001年《程序员》杂志仍然在用大篇幅报道CMM。我都做过……当时一个CMM认证国家补贴80万。好多骗钱的。对反馈的重视,随着商业-科技环境的日益不稳定,终于得到了普遍的认同。现在大家谈的是敏捷、精益,包括在传统上最保守的财务领域也开始谈Beyond Budgeting——本质上就是以滚动预算的方式获得较短周期的投资反馈。我2005年在中国软件行业大会上讲敏捷,台下都听得一愣一愣的。不是反对也不是赞同,是完全不知道讲的啥——一个项目怎么可能做20%就上线给用户用呢?现在这种观念、这种对反馈的重视大家都认同了。本质上这些都是控制论的影响。
大家已经不再提控制论,因为到处都是控制论。
问:我们的世界会变成像《黑客帝国》那部电影一样吗?为什么?
答:要回答这个问题,我们首先得问:黑客帝国描绘的是一个什么样的世界?也许你马上就会说:是人类被机器操纵、只能看到幻象的世界。对,也不对。这个问题不能只从“世界”这边看,同时要从“人”这边看。尼奥能看到真实的世界,不仅仅因为真实的世界存在,而且还因为他选择了红色药丸。换句话说,除了尼奥之外的很多人(尽管不是所有人),之所以看不见真实世界的样子,是因为他们选择了不去看。有一种假象在蒙蔽所有人、并且有很多人主动——有意识或者无意识地——地选择了看到这个假象而非真相,这才是黑客帝国描绘的世界。
从这个意义上来说,我们的世界真的和这个世界很像。比如我随便举个例子好了。你知道年收入10万元在中国是什么收入水平吗?请大家来猜一猜。猜一猜?前3%。
你能相信你公司刚入职每天背个破电脑包挤地铁吃煎饼的那个毕业生是中国前3%的高收入者吗?你能相信你自己是中国前1%甚至前0.1%的高收入者吗?当你看到街上流落的无家可归者、农村背井离乡的打工者,你是否意识到,你自己是造成他们苦难生活的系统中的一部分、甚至是系统的既得利益者?你不需要回答这个问题。因为这种事情就像尼奥的红药丸蓝药丸一样,当你选择了蓝药丸,你就不会看到某些被称为“真相”的事情。
我们这些中产阶级城市知识分子,互联网在我们周围造起了一座回音壁,让我们以为整个世界都是跟我们一样的人,因为我们每天听到的都是跟我们一样的(或者更强的)人发出的声音。然而只要稍微动动脑筋你就会意识到这件事情有多可笑。能在互联网上发出声音的,都是受过良好教育、有着良好经济基础的人。中国90%以上的人在互联网是无声的。你去看看知乎就知道了,你应该能感受到这个回音壁有多牢固。
赵然:全年全国居民人均可支配收入21966元,比上年增长8.9%,扣除价格因素,实际增长7.4%。数据来源:国家统计局2015年的公报。
答:多谢赵然,正想找这个。所以,是的,我的答案非常简单:我们这个世界不需要“变成”,它现在就跟黑客帝国里的世界一样。众多像你一样的人看不见这个世界的真相。真正有意义的问题是,你是否选择看到,以及,当你看到了之后,你会怎么办。
靓汤:我们的思维是建立在这种壁垒之内,我们怎么选择一种积极的,正能量的活法?
答:首先要看到!列宁说的,学习学习再学习!
谢工:我记得熊节好象去非州国家做过项目,是不是有类似的感受经历,因此思考和看书看的很多。
答:对啊。你看到这些人是怎么生活的,然后你以前相信的系统就崩塌了。你就开始想:一个让人去死的系统,不管它多么有道理,终归是不对的吧。
余晟:资本主义和市场经济就是这样。你可能觉得岁月静好,现世安稳。结果远在天边跟你八竿子打不着的某个家伙吃得苦耐得烦,凑巧干了跟你一样的活,也可能他有天赋也可能他要求低,然后你忽然就没活可干了,然后一群人冲上来说:呸,懒鬼,谁让你不努力。
谢工:我们Chat当时和熊节讨论策划一系列的话题,名字叫寻找IT技术史,后来我们找到第一个半个世纪前的大数据时代。
答:谢工这个背景介绍,正好引出下一个问题。
问:数据量没有那么大时通过什么方式提高结果的准确度呢?
答:实际上比尔在设计Cybersyn的时候,有两个原因故意不采集所有巨细靡遗的生产数据。第一,计算资源不足。因为美国的禁运,智利当时只有4台主机,Cybersyn系统只能使用其中的1台。如果采集所有数据,算不过来。IBM 360哟~第二,这是比尔主动的设计。因为如果中央掌握并处理所有数据,那么中央就会对工厂进行微观管理(micro management),那么真正在做事的人就会被跳过、被架空、被剥夺主观能动性。那将是一个机器取代人的系统。Cybersyn从设计的第一天起,在比尔和阿连德的心中,它就是一个为人民服务的系统。
它是一个赋权的系统,不是一个剥夺的系统。话题扯开一点……我认为冷战的终结对人类是一个巨大的损失。因为人类社会从此失去了一个坐标系,只剩下了唯一的坐标系、唯一的维度(历史的终结)。那么在单一坐标系上,人和人、国家和国家,就只有“发达”与“落后”之分,失去了多样性,失去了多角度思考的可能性。
回到大数据和预测系统这里。当我们谈到“准确度”(以及,与它类似的,效率)这个概念,我们不应该把它看做仅有的维度。准确度是多个可能的维度中的一个。其它的维度还包括,比如说,激励人,帮助人。Cybersyn的准确度不高,不仅是条件局限的结果,更是主动权衡、选择了其它维度的结果。我们应该看到设计者选择了什么,而不仅仅看他们放弃了什么。当准确度/效率成为唯一的维度,机器取代人的时机也就到来了。因为准确度/效率不是人的度量,是机器的度量。
问:有关公平创新,包括国家推动全民创业,青少年创业热潮,用本篇文章观点,能否解释一下目的和意义?
答:从一个非常抽象的意义上,可以看到这个问题与本文有一个牵强的关联:科技发展与社会、尤其是与跟不上科技发展的普通劳动者之间的关系。“全民创业”本身的目的非常清晰,一望即知。这就是甩包袱。结构性失业就摆在面前,国家管不了,企业不想管,所以就拿出这么一个招数来甩包袱,让结构性失业的受害者自己承担。当然国家管不了这本身就是1992年深化国有经济改革所追求的结果。说回来。那么这个结构性失业是从何而来?原因有很多,其中一个重要的原因,是机器取代人。机器100年前就取代了人的体力劳动,现在机器开始取代人的脑力劳动和服务性劳动。
机器取代人对谁有利?用创业、创新制造新的增长点,促就业效率又高,成本又低,对资本家有利。机器取代人对谁有害?对那些被取代、被失业却无力再就业的劳动者有害。所以这一波技术发展的趋势,是对掌握资源的极少数强者有利、对不掌握资源的大多数弱者有害。你觉得这种现象、这种行为叫什么?这就叫剥削。这就叫掠夺。你看到的“全民创业”,就是掠夺者吃完肉以后吐骨头的那个动作。
想论证这个观点是否合理,看你身边的“全民创业者”有几个成功——不用多成功,挣钱能赶上房价——就知道了。
georgesuperman:吴军老师说2%的人掌握人工智能。剩下的就会被剥削。
答:然后那2%的掠夺者擦干净嘴唇,对被掠夺的98%说:我也很无奈呀,然而这就是技术发展的必然趋势呀,你说我又能怎么办呢?要不我给你们捐款吧,我做慈善吧?
所以啊。幸亏有像智利的Cybersyn这样的历史在前面,我们才有机会看到:原来科技的发展不一定是以取代人为目的的;原来科技的发展不一定是有利于极少数强者而有害于大多数弱者的;原来科技的发展是可以为人民服务的。
所以,对“全民创业”这种口号(以及强者的慈善捐款),唯一正确的姿态就是对他竖起一根中指说“fuck you”。科技应该属于人民、为人民服务。如果它不是,就革它的命!
魏犇:但是科技是一种工具,请问如何革科技的命?
答:所以我们要研究像Cybersyn这样的历史。历史上是有像阿连德这样的人,想过这样的问题,想得非常深入的。虽然最终被美帝国主义给扼杀了,但是留下了经验和教训给我们。(并向卡斯特罗同志致敬)。
问:控制论下将引导社会向什么样的结构进行演化,会有什么样新的分工,又会有哪些阶层会消逝?
答:这个问题问到了点子上。社会朝哪里演化,不是一个技术的问题。有些未来学者认为科技本身有要求,去研究“科技要什么”,这是很幼稚的。幼稚的地方在于:他假设了政治的缺位。然而政治从不缺位。过去三十年中如果我们看不到政治的存在,仅仅是因为一种政治(美国的政治)占据了垄断地位。现在我们看到了。十几年前有本书很畅销,叫《世界是平的》。现在怎么样?世界是不是平的?打脸打得piapia响。所以(在科技的影响下)社会朝哪里演化,这从来都是一个政治问题。我随便举个身边的例子。
科技可以让出租车司机收入越来越低,工作时间越来越长,越来越无力与公司抗争。但是科技也可以让出租车司机获得体面的收入,与乘客形成良好的互助合作关系,关心环保问题。(感兴趣的同学可以看Green Taxi的案例 )那么为什么我们感觉,科技好像只能朝一个方向去发展人类社会呢?因为那个方向是对资本家有利的。资本家用他们控制的媒体来宣传那个方向,压制别的方向,使我们无法知道有别的方向存在。所以回到这个问题本身:不知道,人类社会发展的可能性有很多很多,我们需要去了解这些可能性,然后主动选择一个对人类有利的可能性,而不是茫茫然地发展到对资本家有利的方向上,然后还以为这是“科技想要的”。
问:如果面对完全透明的同一组大数据,不同的人会得出不同的结论。那么,如何才能假设,只有国家的分析决策,才是正确的呢?换句话说,是不是将数据完全提供给每一个人,交由市场博弈,会更加合理呢?
答:这个问题可以很快速。跟前面问题一样:“正确”是一个政治决策,而不是数学计算。数据可以给每一个人,然而决策不可能给每一个人。还不要说每一个人。乌克兰选个总统,永远都是得票率略高于50%,永远都有另一半人反对他。所谓“市场博弈”这也是个很幼稚的想法。我们看到的从来都是赤裸裸血淋淋的阶级斗争。
庄表伟:还是讨论下吧,别快速过。
答:卡斯特罗去世不是就有一帮住在美国的古巴人弹冠相庆么。
庄表伟:我理解的计划经济,就是由政府,做出一些决策。而那些决策,在市场经济下,应该是由经营者来做的。
答:米塞斯说的所谓“企业家”嘛。然而马云已经意识到这个问题了。马云作为一个企业家,他计划、管控的规模已经超过了世界上很多国家。那么我们有什么理由认为企业家和政府有本质的区别?在管控的效率这个意义上。这正是为什么马云自己在浙商大会上说,我们可能已经摸到计划经济成功的门把手了。
庄表伟:也许不是政府与企业家的区别,而是:作为利益相关方,他是否有权力,为了自己的利益做决策。还是,他被人决策了。或者说,无论是政府,还是马云,他的决策,如果影响了我的利益,我有没有办法?
答:罗纳德高斯的企业理论讲的恰恰就是这么回事:为了追求效率降低交易成本,人们主动度让自己的决策权,这就是企业。
庄表伟:如果,我不但没有办法,还需要拍手称快。还要欢喜赞叹。那就不正常。
王渊命:政府和企业家的本质的区别在于是否掌握暴力机关啊。
答:说得对,但是。未来你对阿里和腾讯不满意的时候,你有选择吗?其实是一回事。统治不一定需要暴力的,也可以通过大数据。
庄表伟:是啊,我可以让渡,也意味着我可以收回。假设,让渡是合理的,收回却不行。那就麻烦了。
Pegasus:企业对员工和国家对公民是有很大区别的。
答:但是,仍然,你说得对。归根结底这是一个政治问题,不是技术问题。解决人民如何当家作主的问题,靠的是政治运动。没有政治运动,那么美国人民一样当不了家做不来主。
王渊命:企业,乃至政府计划的存在是为了降低交易成本,但技术的增长,同时也在降低交易成本。有没有可能技术的发展最终其实是消灭了企业和政府的存在呢?
Pegasus:企业和员工相对更平等。
答:你觉得平等嘛。你觉得你可以选择不跟腾讯和阿里玩嘛。就跟美国人民曾经觉得他们可以选举一样。
问:有关经济预测尤其是宏观经济预测,我在五道口的教授说相信因果逻辑大于相信概率。先因果再以概率。请问老师如何看得宏观经济预测的方法论?
答:这个我一点也不专业,还是避免多说的好。如果说“先因果再概率”是指宏观经济需要预先设计,我完全赞同。中国今天的成就已经充分证明了这一点,如果没有当年的4万亿,哪有今天的顺丰即日达。
问:Cybersyn 这种系统实现的机制有两种,一种是最后完全中心化的,由中心化的一个系统来进行调度和分配,一种是完全去中心化的,因为技术的发展也为完全去中心化带来了可能。熊节老师认为哪种的可能性更大?
答:Cybersyn这个系统,我们要避免用孤立的IT视角去看它。 实际上Beer当时一直把IT系统和人看作整个系统。他提到“Cybersyn”的时候,大部分时候他指的是机器和人的一个整体。从这个意义上来说,Cybersyn是一个结合了中心化和去中心化的系统。
被机器赋权的劳动者分散在各地,做出去中心化的决策。这个视角是我们现在的IT业者非常需要注意的。缺少了对人的重视、没有赋权的出发点,我们做的IT系统就注定是剥夺的系统。
谢工:在寻找IT技术史系列中,熊节目前在这个话题里,是有个系列讲智利的大数据,70年代的互联网变革。挖掘书背后的故事,就是我们讨论的一个方向。虽然现在这类书国内尚未引进,但至少我们可以通过熊节的思考来认识一些本质上发生过的事。
-
半个世纪前的大数据时代
马云在最近的一次公开演讲中谈到市场经济与计划经济的比较:“我们过去的一百多年来一直觉得市场经济非常之好,我个人看法未来三十年会发生很大的变化,计划经济将会越来越大。为什么?因为数据的获取,我们对一个国家市场这只无形的手有可能被我们发现。”这听起来是一个相当大胆、甚至有科幻感的设想:如果能用深入基层的信息终端采集生产和消费数据,用全国连通的网络汇总经济数据,用数据分析软件识别和预测经济异常波动,在国家经济尺度上实时统筹和调整计划,那么近百年来计划经济面临的最大挑战“经济计算问题”有可能得到彻底解决,从而使计划经济有可能成为一种可行的、甚至更优于市场经济的方案。然而更显科幻的是,早在近半个世纪前的1970年代初期,在南美的智利,这样一个意在掌控全国经济的“大数据”系统已经被设计并实现出来了。
* * *
故事从1970年开始。在这一年的智利大选中,萨尔瓦多·阿连德被选为总统,并立即开始推行被称为“智利社会主义之路”的规划。在一系列的改革政策中,最为重要的是对大型企业(包括智利经济支柱的铜矿业)的国有化。这一改革进程很快遭遇了困难,原因不是企业主抗拒国有化,而是国有化进行得太顺利,政府很快发现自己没有足够的人才来对新生的国有企业进行整体调控。面对挑战,阿连德产生了一个大胆的构想:如果仅靠人不足以有效管理国家尺度的经济,再加上技术的支持如何?
阿连德看中的技术是控制论。1948年,控制论这门学科的创始人诺伯特·维纳将其定义为“关于动物和机器中控制和通信的科学”。在二战中,控制论的理论与技术被用于研发防空火控系统——人手操作的高射炮很难准确命中敌方战机,而维纳设计的计算机系统则可以采集敌机飞行的数据、并实时预测敌机的飞行路线、进而自动操作高射炮击中敌机。维纳事后总结,这项研究的核心在于“预测未来”:“预测一个消息的未来,就是用某种算符去运算这个消息的过去……最优预测问题的解决仅仅取决于要加以预测的时间序列的统计性质”。这门新兴学科让阿连德看到了希望:如果控制论可以用于实现防空火控系统这样实时的、复杂的、涉及大量人为因素(驾驶战机的都是由经验丰富且绝对不想被击落的飞行员)的自动化系统,它是否能被用于其他实时的、复杂的、涉及大量人为因素的领域——比如说,经济计划?
在寻找合适的技术领导者的过程中,阿连德的政治乌托邦愿景也吸引了英国控制论学者斯塔福·比尔的兴趣。尽管美国政府对“社会主义”这个字眼极度紧张,不惜以各种政治、经济手段扼杀阿连德的改革政策,阿连德所构想的其实是介于美苏两个超级大国、两种意识形态之间的“第三条路线”,一种既能全面提升智利经济和人民生活水平、又不损害智利保持四十年的民主自由氛围的两全方案。1971年,比尔和阿连德政府开始了合作,在这个政治乌托邦愿景之上又加上了一个科技乌托邦的愿景:构建一个计算机系统来实施调控国家经济——在互联网普及之前二十年。
以维纳为代表的控制论学者经常用人体作为类比。例如维纳这样谈论一个基本的控制论系统:“为了能对外界产生有效的动作,重要的不仅是我们必须具有良好的效应器,而且必须把效应器的动作情况恰当地回报给中枢神经系统,而这些报告的内容必须适当地和其他来自感官的信息组合起来,以便对效应器产生一个适当的调节输出。”比尔则对这一结构进一步深化,提出了“可生存系统模型”的概念。在这一模型中,组成一个系统的各个部件被分为5级子系统:系统1到系统3分别负责感知、信息传导、以及监控和协作的功能,系统4和系统5则负责常规运作层面之上的、有目的的管理和治理职能。比尔用生理学的类比来解释这个模型(如下图),并认为同样的模型也适用于企业和国家经济。
比尔的另一个理论基础是他在1970年的一次主题演讲中提出的“自由机器”理论。所谓自由机器,是这样一种社会-科技系统:它以网络的形式运行,而非层级结构;其中作为行动基础的是信息,而非权力;各个领域的专家知识和实时的信息反馈驱动决策,从而消除官僚体制存在的必要性。比尔甚至构想了在政府机构中这样的自由机器如何实现:它应该是一系列的指挥室,每个指挥室中实时接收和呈现来自各个子系统的信息,指挥室中的各领域专家则基于这些信息提出猜想、并运行模拟程序来验证这些猜想,由猜想汇集而成的决策再从指挥室实时传递到国民经济第一线。
基于可生存系统模型和自由机器理论,比尔的团队向阿连德政府提出了一个系统设计的方案。在他们建议的系统中,国有企业和政府之间会新建起数字化通信的渠道,用于传输实时的生产数据;这些数据随后被送进统计软件程序,用于预测工厂的生产效能,从而使政府能够提前识别和应对异常情况;系统中还包含一个计算机实现的经济模拟器,让政策制订者能够在真正实施他们的经济措施前先在模型中测试;最后,他们还提议建设一个充满未来感的指挥室,让政策制订者们能够聚集在其中,快速掌握国民经济运行的状态,并在数据的支持下快速做出决策。
只有当我们从资料图片中看到这个指挥室,我们才能直观地感受到比尔所说的“未来感”是什么意思。这个建成于1972年的指挥室看上去就像《星际迷航》里“企业号”的舰桥,其中大量塑料与玻璃纤维材质的使用、环绕四周的显示屏、座椅扶手上简洁的操作按钮,都与这个项目的愿景一样,充满了不真实感,就像一部科幻电影。
只是,这不是科幻电影,而是历史上真实存在过的一个IT系统。新生的社会主义智利政府和来自英国的科学家冀望基于这个系统平衡个体自由与自上而下的控制:既保持个人的主观能动性,又使个体为组织(企业或国家)的整体利益共同奋斗、乃至作出必要的牺牲。在智利之外,很多进步人士相信智利能通过经济上的改革探索出一条政治上和意识形态上的“第三条路”,甚至成为冷战的一条出路。阿连德和比尔的IT系统会走向何方,历史在静静注视。
* * *
站在近半个世纪之后回望这段尘封的历史,我会感到一阵莫名的激动。今天IT技术飞速发展,然而我们看见的却是技术日益被掌握在极少数人手里、并被用于为这部分人牟利。技术发展越是日新月异,这道鸿沟就越是触目惊心。难道IT技术的发展就注定伴随着不平等的加剧?难道程序员统治的黑暗世界是无可避免的唯一未来?这一前景让作为技术工作者的我感到灰心。而阿连德与比尔、一个智利人与一个英国人、一个政治家与一个科学家、一个政治乌托邦梦想与一个科技乌托邦梦想的交汇处,这段几乎已被遗忘的历史让我们重新看到希望:为技术赋予政治和社会的正面意义、用技术创造更公正的世界,思考这个问题的不是只有我们。
如果今天的一位IT架构师来设计这个名为“Cybersyn”的系统,也许他会参考IBM的商业技术趋势研究提出一个方案,其中个人移动设备和物联网设备被用于在工厂采集实时的生产数据,数据通过互联网汇集到位于云端的数据库,用大数据和机器学习技术对数据进行加工、分析和预测,并借助社交网络创造政府、企业与工人和谐共处的社会与经济环境。
尽管互联网和手机的时代还有几十年才会到来,比尔提出的方案却与现代的架构方案如出一辙。于是我们不禁要好奇:他所领导的这支团队会如何构建连接厂矿与中央政府的网络,又会用什么技术来实现数据分析与预测功能?当比尔宣称Cybersyn会同时兼顾国家经济运行效率与个人的民主和自由,什么技术能让他掌握全国民众的情绪涨落?在下一篇文章中,我将深入探索Cybersyn系统的设计与实现,敬请期待。
-
喧闹的资本盛宴与无力的慈善
(本文是作者于去年9月应破土网之邀而作的时评。一年时间过去,破土网已不知所踪,腾讯公益日照样红红火火,故此旧文重发,以资记念。)

胜利日的假期还没结束,一位做公益的老友就把我拖进微信群里,要我帮助募捐。仔细一问,原来是腾讯发起了“99公益日”的活动,9月7号到9号的三天时间里,在腾讯公益平台上募捐的项目,捐赠人捐多少,腾讯就对应配捐多少。难怪这位从不直接找我募捐的老友也按捺不住,把我也动员成了“梦想召集人”,给我设定了三天募捐1500元的任务。照他的计划,由他动员的100名梦想召集人每人募集1500元,加上腾讯的一比一配捐,三天内就可以募集到30万元善款。
可世事难预料。9月6号半夜,当我想要开始我这一份募捐时,发现腾讯的乐捐平台慢得打不开。群里一看,大家也都在反映同样的问题。等到一觉醒来,募捐页面倒是可以设置了,当我自己先捐上一百元,却没看到传说中的配捐出现。“99公益日”最大的亮点,就这么爽约了。
正当微信群里大家都在奇怪为什么没有收到配捐,腾讯的官方解释出来了:由于捐款来得太多、太过集中,主办方腾讯不得不临时修改游戏规则,配捐总额9999万,平均分到7、8、9三天,每天3333万。几个小时后,腾讯又召开新闻发布会,继续修改规则:9点开始,单人单日配捐上限999元,项目配捐上限999万元。从这个规则修改不难推测,就在第一天的短短几个小时里,捐款额已经超过了三千万,且已经有机构得到了上千万配捐额度。
随着各路消息在朋友圈里逐渐发酵,一幅完整的图景开始浮现。据某NGO发起人透露,自“腾讯公益99公益日三天1:1配捐乐捐平台上的项目”消息传播开始,很多公益机构摩拳擦掌组建各种战团,准备“冲击99高地”。操作指南出现各种版本,“打劫马化腾”的声音多群可见。别人看阅兵时,很多公益人在加班指导捐助人绑卡。7日凌晨起,第一个5分钟完成配捐超500万,15分钟配捐1000万。有章法的基金会和项目事先确定的战术显著见效,某些知名机构几个小时就入手几百万配捐。集中的捐赠,竟然在午夜时分冲垮了腾讯的IT平台,逼得腾讯临时修改规则。
围观群众有一句点评可谓入木三分:不要高估中国公益人抢钱时的吃相。
在笔者看来,腾讯掀起的这场公益圈的资本盛宴,虽然怀揣着美好的愿景,却也恰好暴露出中国公益行业普遍存在的一个痼疾:众多机构缺乏自己的战略规划和实施计划,一切行动以募款为最大驱动。在腾讯“1:1配捐”的“优惠”政策刺激下,很多人的朋友圈突然间被慈善募捐的信息刷屏。本应言益而非言利的公益机构,却跟着资本的指挥棒一窝蜂团团转,这番情景多少让人有些不忍直视。让这些原本就欠缺高效运营能力的公益机构又多增一次折腾,想来也不是腾讯发起“公益日”活动的初衷。
突然刷屏的募捐广告,更是刷出了慈善捐款这种形式根深蒂固的问题:只有慈善,没有团结。面对铺天盖地的募捐信息,很多中产阶级城市白领不禁要问:难道让他们发善心去帮助弱势群体的动力竟然是“打折”吗?齐泽克将星巴克“买一杯咖啡捐一美元”的慈善计划辛辣地称作“消费主义的最高形态”,因为它通过(更多的)消费来消解中产阶级在消费时的负罪感。而“99公益日”堪称更胜一筹:如果中产阶级(暂时还)没有消费,那么就用打折来创造消费的欲望,并且直接用慈善来消解消费的负罪感。这种集中优惠售卖赎罪券的做法,恰好让我们有机会看清没有共情与团结的慈善还剩下什么——中产阶级需要购买赎罪券来抵消自己卷入和积极参与资本主义体系的负罪感,至于捐赠是用于失学儿童、罕见病患者还是流浪猫狗,又于我何有哉?
在“99公益日”的新闻报道中,腾讯宣称自己的目标是“打造公开透明的公益平台”。仅从这场围抢来看,腾讯在后续需要做的项目监控与信息公布的工作还很多。尤其是精心布置、抢到了上千万配捐额度的机构,这些显然不在其年度计划中的意外收入是否得到有效使用,会是一个引人关注的问题。同时,这场热闹的资本盛宴更让我们看到缺乏共情与团结的慈善是何其无力。公益行业不仅需要募捐平台,更需要一个能以募捐作为桥梁在城市中产阶级与弱势群体之间建立共情与团结的平台。惟有当公益能引领中产阶级走出玻璃办公室,走进被剥削、被压迫、被噤声的弱势群体,体会他们的苦楚,与他们建立团结而非居高临下地施舍,公益才有可能真正创造一个更美好的世界。
-
用技术治病救人,你来不来?
太长不读
如果你想见识非洲、亚洲和拉丁美洲众多发展中国家的丰富与苦难,如果你痛恨这个世界有太多不公,如果你希望用IT技术挽救贫苦人民的生命,如果你有兴趣成为开源软件社区的领导者,如果你想做一个有影响力的软件产品,也许你应该考虑加入Bahmni产品团队,与我们一起用技术治病救人。
你可以在线投递简历,或直接与我联系:JXiong at ThoughtWorks dot com
背景
ThoughtWorks是一家跨国软件设计与定制领袖企业,下属的ThoughtWorks Global Health部门一直致力于推进全球医疗发展。我们积极投身于改善低资源地区的医疗质量,提高医疗服务覆盖率。通过提供技术解决方案、工具、咨询及开源软件的专业知识,我们为亚洲、非洲及拉丁美洲贫穷国家的医疗工作者提供支持,帮助他们为最贫困的人群提供高质量的医疗服务,并帮助这些国家的政府进行医疗体系的全局优化。
Bahmni是ThoughtWorks Global Health的拳头产品。这个开源的医院信息化系统(HIS)可以部署在全世界最贫困地区的医院,帮助那里的医生提高工作效率、减少诊疗错误、优化医疗决策、完善数据汇报。迄今为止,Bahmni已经在印度、孟加拉、尼泊尔、塞拉利昂等国的多家乡村医院实施,获得了极佳的反响。
作为ThoughtWorks全球医疗战略布局的重要环节,我们计划在中国建立一支Bahmni产品研发团队。这支团队将与分布在世界各地的全球医疗团队紧密协作,为Bahmni的实施和产品演进做出关键贡献。我们的目标是十年内在全球5000家最贫困地区的医院实施Bahmni系统,提升全世界最贫困人群的医疗服务水平。
为此,我们将招聘Bahmni产品研发团队的三个核心角色:产品经理,软件架构师和实施经理。
产品经理
职位要求
- 具备医疗信息化行业工作经验,有较丰富的行业知识积累
- 熟悉医疗行业主流业务流程及相关IT系统
- 有从事EMR/CIS/HIS相关工作经验者优先
- 良好的产品分析总结归纳能力,熟悉产品运营;
- 具有较强的语言表达沟通能力,具备良好客户沟通和管理能力
- 具有团队精神,较强的组织协调能力,性格稳重扎实
- 习惯分布式团队协作,英语书面及口头沟通能力佳者优先
- 熟悉敏捷需求管理及项目管理流程者优先
工作内容
- 理解并分析贫穷地区医院需求,协调客户关系,保障医疗信息化项目实施
- 综合分析客户需求,把控医疗信息化产品规划方向
- 与分布在全球多个国家的医疗信息化产品团队协作,共同保障产品研发及演进
- 协调位于中国的产品交付和实施团队,负责需求传递及成果验收
- 代表公司参加国内及国际各类行业相关会议,发表演讲及文章
软件架构师
职位要求
- 4年以上开发经验,2年以上团队技术主导者经验
- 有设计、规划、实现复杂业务系统的工作经验
- Java基础扎实,精通常用主流基础框架
- 熟悉Web系统的设计和部署
- 有较强的分析设计能力、方案整合能力和解决问题能力
- 良好的团队合作精神,自我驱动,勤奋好学
- 具有医疗信息化行业工作经验者优先
- 习惯分布式团队协作,英语书面及口头沟通能力佳者优先
- 具有开源项目工作经历者优先
- 熟悉敏捷软件开发流程和实践者优先
工作内容
- 理解贫穷地区医院需求,制订技术方案,保障医疗信息化项目实施
- 与产品经理紧密协作,把控医疗信息化产品技术架构方向
- 与分布在全球多个国家的医疗信息化产品团队协作,共同保障产品研发及演进
- 领导位于中国的产品交付和实施团队,形成高效、高质量交付
- 与世界各地的开源社区领袖协作,共同构建全球医疗IT生态系统
- 代表公司参加国内及国际各类行业相关会议,发表演讲及文章
实施经理
职位要求
- 4年以上实施经验,2年以上领导实施团队经验
- 熟悉LINUX操作系统及相关的服务和排错方法
- 熟悉网络相关的基础知识
- Java基础扎实,了解常用主流基础框架
- 具有较好的软件理解和应用能力,能够清晰的向客户传达软件使用方法,进行用户使用培训和指导
- 有较强的责任心和自我驱动能力,良好的团队合作精神,勤奋好学
- 习惯分布式团队协作,英语书面及口头沟通能力佳者优先
- 具有EMR、HIS实施经验者或具有医疗信息化行业工作经验者优先
工作内容
- 管理和发展产品实施团队;
- 负责客户项目的软件产品和相关设备的配置、部署及相关技术实施工作;
- 实施过程中用户培训、需求调研、系统测试等工作;
- 负责项目实施技术文档、运维资料的编写与归档;
- 配合销售人员进行必要的业务交流、客户资源调研、售前方案编写等售前工作;
- 与世界各地的开源社区领袖协作,共同构建全球医疗IT生态系统
-
微服务与康威定律
(本文是对《Building Microservices》一书第10章的摘录)
康威定律
Melvin Conway于1968年发表的论文《How Do Committees Invent》指出:系统设计的结构必定复制设计该系统的组织的沟通结构。这一论断被称为“康威定律”。在《Exploring the Duality Between Product and Organizational Architectures》一文中,作者发现紧密耦合的组织(例如典型的商业产品公司,所有员工在同一地点工作,具有高度一致的愿景与目标)开发的软件倾向于较少模块化,而松散耦合的组织(例如分布式的开源社区)开发的软件则倾向于更加模块化、耦合较少。
当一支小型团队负责整个系统的设计与实现时,团队内部可以具有频繁的、细粒度的沟通。而随着团队变大、分布在不同地点甚至时区,协调变更成本急剧增加,紧跟着就有两种可能性:人们要么找到降低协作/沟通成本的办法,或是停止做变更。后者就会导致庞大、难以维护的代码库。最终,各个地点不得不选择各自专门处理的一部分工作,拥有一部分代码,并在团队之间形成更粗粒度的沟通机制。组织结构中的沟通路径会造就与之对应的粗粒度API,形成代码库各个大块之间的边界。
服务的边界应该围绕着约束上下文(bounded context)来画,正如我们希望团队结构与约束上下文保持一致。这样做有几方面的好处。首先,团队在一个约束上下文内更容易抓住领域概念;其次,一个约束上下文内的多个服务更可能彼此交互,因此系统设计和发布协作都得以简化;最后,交付团队与业务代表沟通时,团队只需与各自约束上下文中的一两个专家建立良好关系即可。
服务所有权
一般而言,每个服务属于一个团队,拥有这个服务的团队负责其所有修改。这个团队可以任意调整代码结构,只要这些修改不对服务的消费者造成破坏即可。在很多团队中,“所有权”延伸到了服务的各个方面,从需求来源直到软件的构建、部署和维护。由同一个团队负责开发、部署和维护会促使他们简化部署环节,而不是“写完代码扔过墙”。
有很多团队采用“共享服务所有权”的模式。这种模式并不理想,但有必要了解团队为什么做此选择。常见的理由包括:
- 难以拆分。《Building Microservices》一书的第5章提供了一些关于如何拆分服务的建议。也可以考虑把团队合并,从而使组织结构与软件架构匹配。
- 特性团队。比起传统的“按技术/职能划分团队”的IT组织结构,“一个团队端到端负责一个特性开发”的结构是一个进步。然而微服务环境下的团队结构可以再向前一步:如果业务领域、服务边界、团队结构三者能保持对齐,一个团队就能聚焦一组客户,以整体视角为这组客户提供服务。横切多个业务领域的修改固然会发生,但可能性会降低很多。
- 交付瓶颈。有几个办法可以应对交付瓶颈而不必共享服务所有权。第一个办法就是等待,各个服务不一定要以同样的节奏发布,遇到交付瓶颈的服务可以稍后再发布。另外,也可以直接向有交付困难的团队中加人。横跨整个组织的技术栈越标准,临时加人的效果就会越好。当然,另一方面,标准化的技术栈也可能给团队造成束缚。
内部开源
通常的开源项目组织方式可以用在企业内部:一个代码库由一组受信任的提交者(核心团队)管理,并接受未获信任的提交者(外围团队)提交的修改。开源项目以这种方式来保障代码质量和一致性。大多数开源项目在第一个核心版本成型之前倾向于不接受外来的提交。当服务变得成熟且稳定,便可以更放心地开放接受贡献。
分布式版本控制工具允许任何人提交pull request,这是很重要的能力。取决于组织的规模,内部开源体系可能需要考虑借助代码评审工具来讨论和评估是否接受pull request。同时,类似于github提供的pull request评论功能也很有用。最后,需要让提交者很容易构建和部署整个软件,通常这需要定义良好的构建和部署流水线,以及集中管理的构建产物仓库。
案例:REA
REA的服务由“小队”(squad)拥有,小队负责服务的整个生命周期,包括构建、测试、发布、支持、直到下线。一支交付服务团队给这些小队提供建议和指导,以及必要的工具支持。REA有着强烈的自动化文化,并大量使用AWS使团队更具自主性。
不仅交付团队与业务经营对齐,软件架构也是一样。以服务集成为例:在一条业务线内部,所有服务可以用任何方式自由交流,小队自己可以做决定;然而在业务线之间,所有交流必须以异步批处理的形式发生,这是中央架构团队规定的很少几条“铁律”之一。粗粒度的系统集成与业务线之间已有的粗粒度交流相匹配。
人
为了对齐业务经营,组织结构和软件架构都需要改变。变革的阻力真实存在:从大一统的系统转到微服务,对于习惯了单一编程语言、不用考虑运维问题的开发者而言是一次痛苦的觉醒;习惯了把软件“丢过墙”的程序员突然发现没有别人可以推诿责任,可能会很不习惯自己对所有工作负责;如果要让开发者承担7*24在线支持工作,甚至可能有劳动合同上的阻碍。变革推动者需要理解员工的喜恶,顺势而为,不能急于求成。
-
机器学习:概述
本文摘录了一组关于机器学习的介绍文章,帮助非技术性的读者快速了解机器学习的目的、原理和用途。

为什么要机器学习?
机器学习有望解决传统企业软件解决方案的很多问题。首先,在传统企业软件中,数据的质量受限于人类的输入。然而现实是,大部分销售不喜欢更新CRM系统中的数据,真正的销售数据只存在于若干电话会议与数字表格中。同时,传统的企业系统大多构建于关系型数据库上,而关系型数据库并不善于表现信息的时间轴视图,因此大多数企业需要依赖于庞大的数据仓库来不断接收来自企业系统的数据转储。使用这种方法,业务人员必须等待几周甚至几个月才能从数据团队得到有用的洞见。最后,传统的企业系统依赖于成千上万人定的规则,而这些规则是静态的,在业务发展的过程中会逐渐失效。
(来源:Crunch Network | The Next Wave Of Enterprise Software Powered By Machine Learning)
机器学习的发展可以分作三个阶段:机器学习1.0是“描述”(description),2.0是“预测”(prediction),3.0是“对策”(prescription)。今天的CxO们大约不用太操心“描述”阶段,大多数企业已经拥有对应的IT系统。眼下他们迫切需要拥抱“预测”阶段。今天的科技不仅能让业务人员查看历史数据,而且能预测未来的行为和结果。
(来源:McKinsey | An executive’s guide to machine learning)
机器学习如何工作?
简单说,机器学习是一类自我改进的算法。计算机从一个模型开始,用试错法反复训练这个模型,然后就可以做出预测,例如预测某一笔金融交易有多大风险。以侦测信用卡欺诈的机器学习算法为例,首先要用大量真实持卡人的交易记录来训练这个模型,并根据历史记录对模型调优。接下来,信用卡交易就会实时地流过这个算法模型,算法模型则对每条交易记录生成一个概率数据,代表该笔交易涉及欺诈的可能性(例如97%)。如果欺诈侦测系统被配置为阻止欺诈概率95%以上的交易,那么这个评估值就会引发POS机拒收这张信用卡。
在判断交易是否欺诈时,机器学习算法会考虑很多因素:商家的可信度、持卡人的购买行为、时间、地点、IP地址等等。数据点越多,预测就会越准确。人类不可能在几分之一秒内评估几千个数据点,只有自动化的算法能让实时的欺诈侦测成为可能。
(来源:The Conversation | Machine learning and big data know it wasn’t you who just swiped your credit card)
机器学习与传统的数据统计有一个重要的区别:使用机器学习时,我们并不关心因果性(causality)。我们可能并不关心什么变化造成什么结果,而是聚焦于预测:只要有一个模型能在当前环境下给出准确的判断就行。可以参考我们如何使用天气预报:天气预报并不告诉我们降雨的原理,只告诉我们下雨的概率,我们参照这个概率判断是否应该带伞出门。机器学习也是一样:个性化推荐就是对人们偏好的预测,尽管并不知道人们为什么喜欢这些东西,但这种预测是有用的。习惯了这个思维方式以后,机器学习的价值就会显而易见。
(来源:HBR | What Every Manager Should Know About Machine Learning)
机器学习用来干嘛?
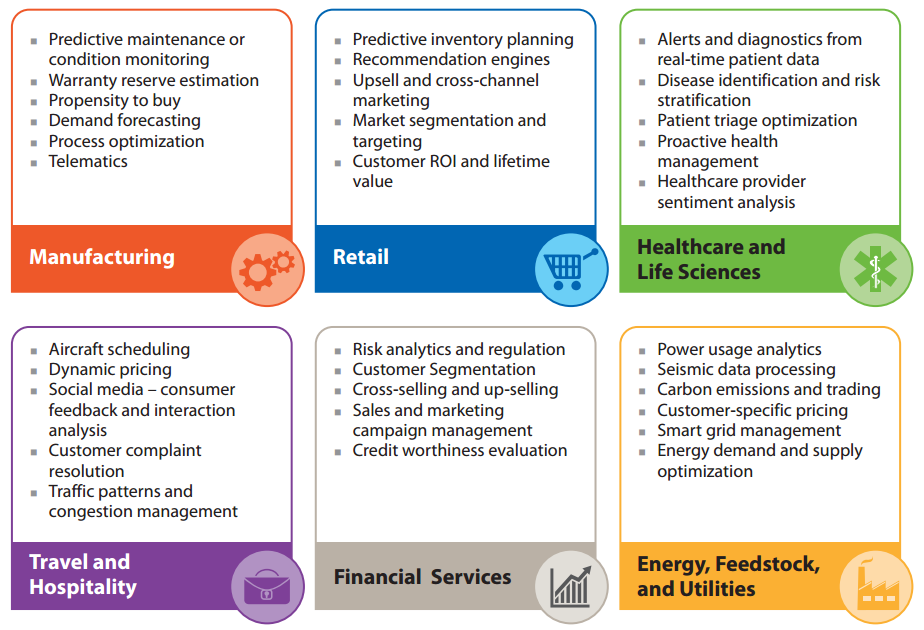
(来源:Tata Consultancy Services | Using Big Data for Machine Learning Analytics in Manufacturing)在银行里应用机器学习技术提供个性化服务:
- 基于顾客的信用卡/银行卡使用模式给出推荐;
- 基于顾客在特定产品/网站上的行为给出推荐;
- 预测顾客下一步可能的消费行为;
- 如果顾客错过了航班,预测他们立即的需要;
- 向顾客推荐有折扣的商品、餐馆、酒吧等;
- 根据顾客的还款周期及时推送时尚信息
(来源:Kathiravan Manoharan | Applications of Machine Learning Algorithms in Banking)
应用在金融服务领域,机器学习算法可以揭示新的消费模式、识别未知的交互方式、发现新的顾客群体、获得新的洞见,从而助力银行的全渠道建设。
(来源:Strands Finance | Transparent technology: How machine learning brings magic to next-generation PFM)
我们调查了168家年收入5亿美元以上企业的执行官,76%表示机器学习可以通过从大数据中持续学习和优化给销售人员的实时推荐而带来销售增长。超过4成的企业已经开始在销售与市场领域实施机器学习。我们的研究显示,大企业在销售流程中应用机器学习有三个维度:首先是提供数据和流程的可见性,使销售过程更加科学;另外是在销售与市场环境中开展更多数据驱动的实验;第三是通过自动化事务性流程来最大化实际销售活动的时间占比。
在采用机器学习之前,决策的主要依据是静态的数据库、针对历史数据的分析、经验和直觉。机器学习可以用实时数据来驱动决策,并且持续改进预测质量。假说可以快速被提出、测试、调整、并最终用于改进工作流程。在我们的调查中,接近80%的企业认为机器学习显著提升了销售关键绩效指标。
(来源:Sloan Review | Sales Gets a Machine-Learning Makeover)

(来源:Yandex Data Factory)麦肯锡使用机器学习算法扫描超过1万份应聘者简历,预测出来的招聘结果与真实结果高度相关。有趣的是,机器学习算法接受了比真实招聘略多的女性应聘者,也许将来技术可以有效地消除人类面试官隐藏的偏见。
(来源:McKinsey | An executive’s guide to machine learning)
-
深蓝与AlphaGo的对比
20年前,深蓝与卡斯帕罗夫的对弈使人工智能进入大众视野;20年后,AlphaGo对李世乭的压倒性胜利再次使人工智能成为热议焦点。同样是战胜了棋类世界冠军,两代人工智能最重要的差别在于:深蓝仍然是专注于国际象棋的、以暴力穷举为基础的特定用途人工智能,而AlphaGo是几乎没有特定领域知识的、基于机器学习的、高度通用的人工智能。这一区别决定了深蓝只是一个象征性的里程碑,而AlphaGo则更具实用意义。

深蓝的算法
整体而言,深蓝是一套专用于国际象棋的硬件,大部分逻辑是以“象棋芯片”(Chess Chip)的形式用电路实现的。在象棋芯片之上,有较少量的软件负责调度与一些高阶功能。
深蓝算法的核心是基于暴力穷举:生成所有可能的走法,然后执行尽可能深的搜索,并不断对局面进行评估,尝试找出最佳走法。深蓝的象棋芯片包含三个主要的组件:走棋模块(Move Generator),评估模块(Evaluation Function),以及搜索控制器(Search Controller)。各个组件的设计都服务于“优化搜索速度”这一目标。
走棋模块负责生成可能的走法。走棋模块的核心是一个8*8的组合逻辑电路阵列,代表棋盘的64个格子。国际象棋的走棋规则以硬件电路的方式嵌入到阵列之中,因此走棋模块可以给出合法的走法。在核心之外还有附加的逻辑电路用于探测和生成特殊走法(例如“吃过路兵”和“王车易位”)。
评估模块是整个芯片中最主体的部分,占据了芯片上2/3的面积、超过半数的逻辑三极管和80%以上的存储三极管。评估模块又分为三个部分:棋子位置评估;残局评估;以及慢速评估。棋子位置评估对盘面上所有棋子当前所处的位置计分,不同棋子处于不同位置的分值由软件预先计算好后写入硬件。芯片中输入了大约8000种不同的“模式”,并针对每种模式赋予了一定的分值。残局评估也预存了一系列专门针对残局的估值规则,例如“王在棋盘中央有利”(King centralization bonus)的规则。残局评估子模块还以8*8组合逻辑电路阵列的形式跟踪所有兵所处的位置,并计算兵是否越过了对方的王、是否能一路冲到对方底线晋级。由于逻辑嵌入在硬件中,棋子位置评估和残局评估都只需要一个时钟周期就可以完成计算。
慢速评估子模块是整个芯片上最复杂的元素,占据芯片上约一半的面积,并且完成计算需要10个时钟周期。大量国际象棋特有的逻辑都在慢速评估的过程中计算,包括:
square control, pins, xrays, king safety, pawn structure, passed pawns, ray control, outposts, pawn majority, rook on the 7th, blockade, restraint, color complex, trapped pieces, development and so on
搜索控制器实现了一个最小窗口alpha-beta搜索算法(minimum-window alpha-beta search algorithm),也称为alpha-beta剪枝算法,能快速削减搜索的规模。
深蓝的软件也是专门设计用于与硬件协同工作的。软件部分负责调度最多32个象棋芯片并行搜索,并负责对大范围规划的局面进行软件评估。深蓝的软件还连接了“仅剩5子”的残局数据库,一旦出现仅剩5子的残局,就会直接从这个数据库中搜索最佳走法。软件中还包含了从30万局棋中抽取出来的开局书,并且工程师还不断优化其中记录的开局走法。
AlphaGo的算法
AlphaGo是一个能够运行在通用硬件之上的纯软件程序。据称其中部分程序使用了TensorFlow。
AlphaGo的核心算法基于机器学习。在训练的第一阶段,AlphaGo仅仅根据彼此无关的盘面信息模仿专家棋手的走法。通过3000万个盘面数据训练一个13层的监督式策略网络,这个神经网络随后就能以超过50%的精度预测人类专家的落子。值得注意的是,在这一阶段,AlphaGo对于围棋规则一无所知,只是毫无目的地模仿而已。尽管如此,由于违反规则的走法(例如“自杀”)专家棋手不会走出,所以AlphaGo也相当于学会了遵守围棋规则。
在训练的第二阶段,AlphaGo开始与自己下棋:将过往训练迭代中的策略网络与当前的策略网络对弈,并将对弈过程用于自我强化训练。在这一阶段,引入了唯一的围棋规则:对获胜的棋局加以奖励。经过这一阶段的训练,AlphaGo已经超过所有围棋软件,对弈当时最强的开源围棋软件Pachi可以达到85%胜率。
在训练的第三阶段,AlphaGo在自我对弈中,从不同棋局中采样不同位置生成3000万个新的训练数据,用以训练局面评估函数。经过三阶段训练的策略网络被混和进蒙特卡洛树搜索算法,从而在比赛进行过程中预测棋局未来可能的发展方式、并对各种可能的未来局面进行评估。
在整个算法中,只有“获胜”这个概念作为围棋规则被输入训练过程,除此之外AlphaGo对于围棋规则一无所知,更没有高级围棋专门概念(例如“定式”)。尤其是第一阶段的训练,完全基于简单的盘面信息训练达到相当可观的预测效果,这一过程在很多需要“预测”这一功能的领域具有显著的意义。
规模与复用
深蓝的一枚象棋芯片包含大约1百万个三极管,其中逻辑三极管45万个、存储三极管55万个。该芯片采用0.6微米CMOS技术,主频30~40兆赫。1997年与卡斯帕罗夫对弈并获胜的深蓝II是一台30个节点的RS/6000超级计算机,每个节点上部署16枚象棋芯片,共计480枚象棋芯片并发。由于内嵌大量国际象棋专用逻辑、且采用硬件方式实现,深蓝对于IBM后续的人工智能(例如Watson)并无太多可复用性。
AlphaGo使用的硬件则要强大得多。与李世乭对弈的分布式版本使用了1920颗CPU和280颗GPU,并且据称该版本的AlphaGo已经使用了Google自制的“张量处理单元”(TPU)。Google宣称这种芯片专门针对TensorFlow优化,其计算效率比GPU高出一个数量级。由于几乎不包含领域特定知识、且运行于通用硬件基础上,AlphaGo的软件据信非常简单(一个开源项目仅用约1200行代码就实现了AlphaGo的核心算法),且其中大部分算法可以解决用于其它领域的机器学习问题。
参考资料
- Campbell, M., Hoane Jr., a. J., & Hsu, F. (2002). Deep Blue. Artificial Intelligence, 134(1-2), 57–83.
- Ferrucci, D., Brown, E., Chu-Carroll, J., Fan, J., Gondek, D., Kalyanpur, A. a., … Welty, C. (2010). Building Watson: An Overview of the DeepQA Project. AI Magazine, 31(3), 59–79.
- Hsu, F., Campbell, M., & Hoane, J. (1995). Deep Blue system overview. In ICS ’95: Proceedings of the 9th international conference on Supercomputing (pp. 240–244).
- Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., … Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484–489.
